[빅데이터를 지탱하는 기술] 4장_빅데이터 축적
1. 벌크 형과 스트리밍 형의 데이터 수집
데이터 수집 방법으로 두 가지 방법이 있다.
이 챕터에서는 각각의 방법으로, 분산 스토리지에 데이터가 저장되기까지의 흐름을 정리한다.
- 벌크 형
- 스트리밍 형
객체 스토리지와 데이터 수집
빅데이터는 확장성이 높은 분산 스토리지에 저장된다. 분산 스토리지로,
분산형 데이터베이스
객체 스토리지
객체 스토리지는 다수의 컴퓨터를 사용해 파일을 여러 디스크에 복사해서 데이터 중복화 및 부하 분산을 실현한다.
객체 스토리지의 구조는 데이터 양이 많을 때는 우수하지만, 소량의 데이터에 대해서는 비효율적이다.
하둡의 HDFS, 클라우드 서비스의 Amazon S3 가 대표적이다.
데이터 수집
데이터 수집이란, 수집한 데이터를 가공해 집계 효율이 좋은 분산 스토리지를 만드는 일련의 프로세스이다.
작은 데이터는 적당히 모아서 하나의 큰 파일로 만들어 효율을 높이는데 도움이 된다.
파일이 지나치게 크면, 네트워크 전송 시간이 오래 걸려 오류 발생률이 높다.
벌크 형 데이터 전송
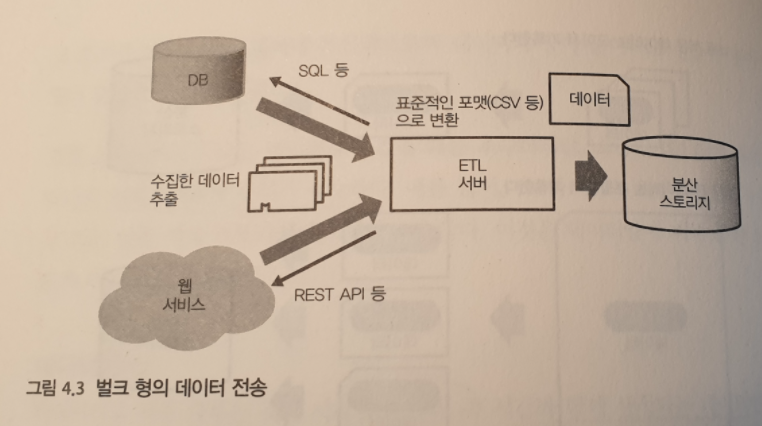
전통적인 데이터 웨어하우스에서는 주로 벌크 형 방식으로 데이터베이스나 파일 서버 또는 웹 서비스 등에서 각각의 방식 (SQL, API …) 으로 정리해 데이터를 추출한다.
처음부터 분산 스토리지에 데이터가 저장되어 있지 않으면 데이터 전송을 위한 ETL 서버를 설치한다.데이터 전송의 신뢰성이 중요하면 벌크형 도구를 사용하는 것이 좋다.
파일 사이즈의 적정화
ETL 프로세스는 하루마다 또는 한시간 마다의 간격으로 정기적인 실행을 하므로 그 동안 축적된 데이터는 하나로 모인다.
데이터 양이 많을 때는 한 달씩이나 하루 단위로 전송하도록 작은 태스크로 분해해 한 번의 태스크 실행이 커지지 않도록 조정해야한다.
워크 플로우 관리 도구를 사용하면 쉽게 관리 할 수 있다.
스트리밍 형의 데이터 전송
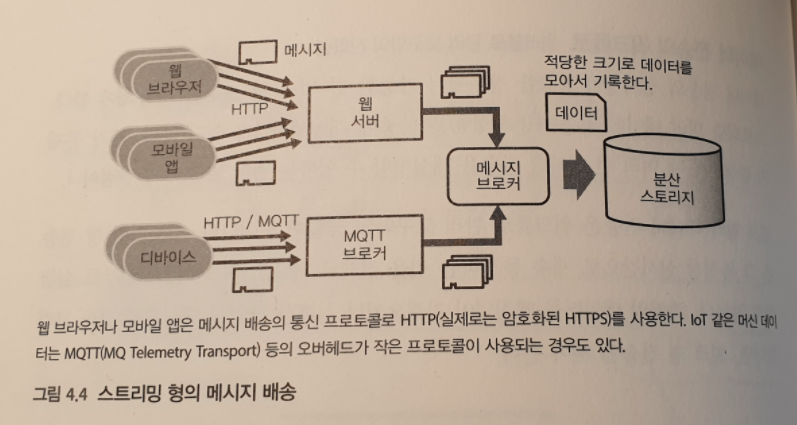
계속해서 전송되어 오는 작은 데이터를 취급하기 위한 데이터 전송이다.
이러한 데이터 전송은 다수의 클라이언트에서 계속 작은 데이터가 전송된다. 이러한 데이터 전송 방식이 메세지 배송 (Message Delivery) 이다.
보내온 메세지를 저장하는 방법으로,
- NoSQL 데이터베이스
Hive 와 같은 쿼리 엔진으로 NoSQL 데이터베이스에 연결해 데이터를 읽을 수 있다. - Message Queue
데이터를 일정 간격으로 꺼내고 모아서 분산 스토리지에 저장한다.
웹 브라우저에서 메세지 배송
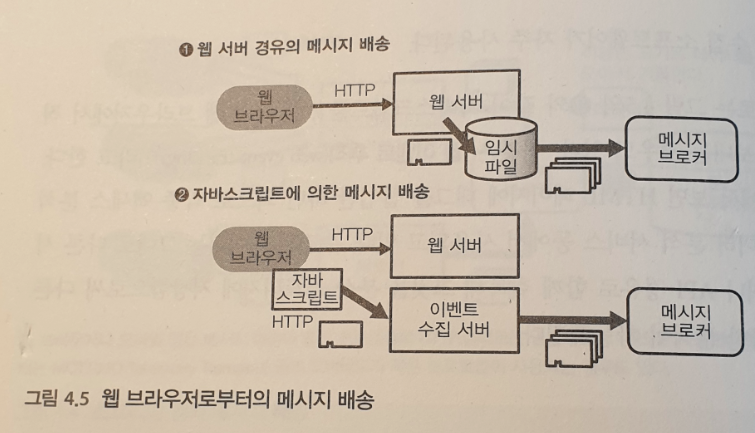
- 상주형 로그 수집 소프트웨어
자체 개발한 웹 애플리케이션 등에서는 웹 서버 안에서 메세지를 만들어서 배송한다.전송 효율을 높이기 위해 서버상에서 일단 데이터를 축적해 놓고 나중에 모아서 보내는 경우가 있다.
이 때, Fluentd 나 Logstash 같은 상주형 로그 수집 소프트웨어가 자주 사용된다. - 웹 이벤트 추적
자바스크립트를 이용해 웹 브라우에서 직접 메세지를 보내는 경우도 있다.
모바일 앱에서 메세지 배송
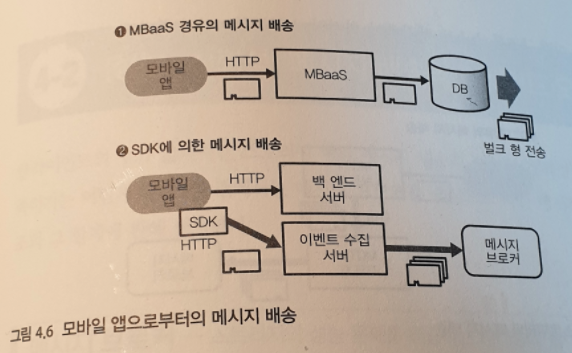
- MBaaS
모바일 앱에서는 서버를 직접 마련하는 것이 아니라, MBaaS (Mobile Backend as a Serivce) 라는 백엔드의 각종 서비스를 이용할 수 있다. - SDK
모바일 앱이 오프라인이 되었을 때는 발생한 이벤트를 SDK 내부에 축적하고 온라인 상태 되었을 때 모아서 보낼 수 있다.
디바이스에서 메세지 배송
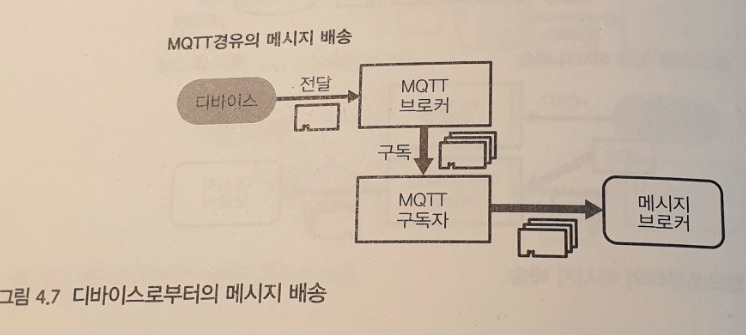
MQTT (MQ Telemetry Transport) 는 TCP/IP 를 이용하여 데이터 전송하는 프로토콜 중 하나이다. 일반적으로 Pub/Sub 메세지 배송 구조이다.
메세지 배송의 공통화
메세지가 처음 생성되는 기기를 클라이언트, 해당 메세지를 먼저 받는 서버를 프론트엔드라고 한다.
프론트 엔드는 단지 데이터를 받는 것에 전념하고, 그 이후의 문제는 백엔드의 공통 시스템에 맡길 수 있다.
2. 성능, 신뢰성 : 메세지 배송의 트레이드오프
이 챕터는 메세지 브로커를 중심으로 메세지 배송 구조와 한계를 정리한다.
메세지 브로커
메세지 배송에 의해 보내진 데이터를 분산 스토리지에 저장할 때, 데이터 양이 적을 때는 문제가 되지 않지만 쓰기의 빈도가 증가하면 디스크 성능의 한계에 도달해 더 쓸 수 없게 될 우려가 있다.대량의 메세지를 안정적으로 받기 위해서는 빈번한 쓰기에도 견딜 수 있는 성능이 높고, 필요에 따라 성능을 얼마든지 올릴 수 있는 스토리지가 필요하다.분산 스토리지가 반드시 이 성격을 가질 수 있다고 할 수 없기 때문에, 메세지를 일시적으로 축적하는 중산층이 설치된다. 이것이 메세지 브로커이다.
ex) Apache Kafka, Amazon Kinesis
push 형, pull 형
송신 측의 제어로 데이터를 보내는 방식을 push 형, 수신 측 주도로 데이터를 가져오는 것을 pull 형이라고 한다.
메세지 브로커에 데이터를 push 하는 것을 producer, pull 하는 것을 consumer 라고 한다.
push 형의 메세지 배송은 모두 메세지 브로커에 집중 시키고 거기에서 일정한 빈도로 꺼낸 데이터를 분산 스토리지에 기록한다.
또한, pull 형의 메세지 배송은 파일 사이즈 적정화에도 도움이 된다. consumer 는 메세지 브로커로부터 일정한 간격으로 데이터를 취해 적당히 모아진 데이터를 분산 스토리지에 저장한다.
메세지 라우팅
메세지 브로커에 써넣은 데이터는 다수의 다른 consumer 에서 읽을 수 있다. 이를 통해 메세지가 복사되어 데이터를 여러 경로로 분기 시킬 수 있다. 이것이 메세지 라우팅이다.
예를 들어, 메세지 일부를 실시간 장애 감지를 사용하면서, 같은 메세지를 장기적인 데이터 분석을 위한 분산 스토리지에 저장하는 것도 가능하다.
메세지 배송 신뢰성 문제와 세 가지 설계 방식
대부분의 경우 다음 중 하나를 보장하도록 설계된다.
- at most once
기껏해야 한 번.
메세지는 한 번만 전송된다. 도중에 전송 실패로 사라질 가능성이 있다. - exactly once
정확히 한 번.
메세지는 손실 되거나 중복 없이 한 번만 전달된다.
네트워크 상에 두 개의 노드가 있는 경우 양쪽의 통신 내용을 보장하기 위해 coorninator 가 필요하다. 문제가 생기면 송신 측과 수신 측 모두 서로의 정보를 코디네이터에게 전달해서 문제가 발생하면 코디네이터의 지시에 따라 해결할 수 있다.
그러나 분산 시스템에서는 코디네이터와의 통신이 끊길 수 있고 코데네이터가 정지될 수도 있다. 따라서 코디네이터의 부재 시에 어덯게 할 것인지에 대한 consensus 가 필요하다. 보통, 단시간 장애 가능성은 받아 들인다.
또한, 코디네이터의 판단에만 따르고 있으면 시간이 너무 소요된다.
그래서 메세지 배송 시스템에서는 코디네이터를 도입하지 않고 at least once 를 따른다. - at least once
최소한 한 번.
메세지는 확실히 전달된다. 단, 같은 것이 여러번 전달될 가능성이 있다.
메세지가 재전송되어도 그것을 없앨 수 있는 구조가 있으면 보기에 중복이 없는 것처럼 할 수 있다. 이러한 구조를 ‘중복 제거’ 라고 한다.
예를 들어, TCP 는 메세지 수신 확인을 위해 ‘ack’ 플래그를 도입했다. 메세지 재전송에 의한 중복이 발생하지만, 모든 TCP 패킷에서는 이것을 식별하는 시퀀스 번호를 이용해 중복 제거가 이뤄진다.
대부분의 메세지 배송 시스템은 at least once 를 보장하는 한편, 중복 제거는 이용자에게 맡기고 있어서 TCP/IP 처럼 자동으로 중복을 제거해주지 않는다. (ex) Apache Kafka, Apache Flume, Logstash
중복 제거는 높은 비용의 오퍼레이션
중복 제거 방법으로 다음과 같은 방법이 있다.
오프셋 이용
각 메세지에는 파일 안의 시작 위치 (오프셋) 를 붙인다.
메세지가 중복되어도 같은 파일의 같은 장소를 덮어쓸 뿐이므로 문제되지 않는다.
벌 크형 데이터 전송과 같이 데이터양이 고정된 경우에 사용한다.고유 ID 이용
모든 메세지에 UUID 등의 고유 ID 를 지정한다.
메세지가 늘어남에 따라 ID 가 증가하므로 그것을 어떻게 관리하느냐가 문제이다.
스트리밍 형의 메세지 배송에서 자주 사용된다.
End to End 신뢰성
클라이언트가 생성한 메세지를 최종 도달 지점인 분산 스토리지에 기록하는 단계에서 중복 없는 상태로 해야한다.
중간에 한 부분이라도 at most once 가 있으면 메세지를 빠뜨릴 가능성이 있고, at least once 가 있으면 중복될 수 있다.
신뢰성이 높은 메세지 배송을 실현하려면 중간 경로를 모두 at least once 로 통일한 후 클라이언트 상에서 모든 메세지에 고유 ID 를 포함하도록 하고 경로의 말단에서 중복 제거를 실행해야한다.
고유 ID 를 사용한 중복 제거 방법
두가지 방법이 있다.
분산 스토리지로 NoSQL 데이터베이스 사용
Cassandra 나 Elasticsearch 등은 데이터를 쓸 대 고유 ID 를 지정하게 되어 있어 동일한 ID 의 데이터는 덮어쓴다.SQL
보내온 데이터는 일단 그대로 객체 스토리지 등에 저장하고, 나중에 읽어 들이는 단계에서 중복을 제거한다.
Hive 와 같은 배치형 쿼리 엔진에서 실행할 수 있다.
데이터 수집 파이프라인
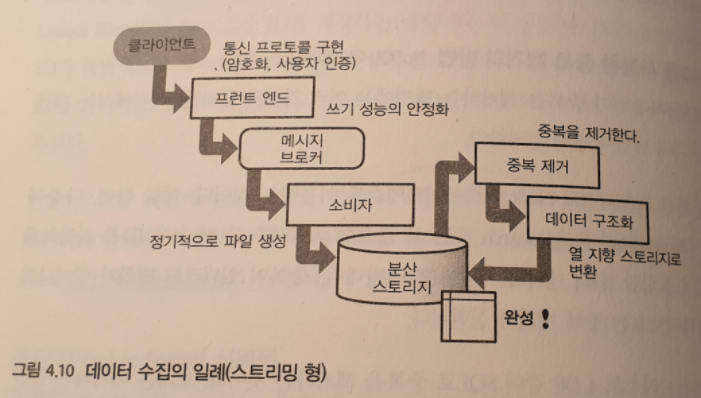
일련의 프로세스를 거쳐 마지막으로 데이터를 구조화해서 열 지향 스토리지로 변환함으로써, 장기간의 데이터 분석에 적합한 스토리가 완성된다. 이것인 데이터 수집 파이프라인이다.
실제로 어떤 파이프라인을 만들지는 요구사항에 따라 다르므로, 필요에 따라 시스템을 조합한다.
예를 들어, 쓰기 성능에 불안감이 없으면 메세지 브로커가 불필요 하므로 클라이언트에서 직접 NoSQL 데이터베이스에 데이터를 써도 된다. 중복이 허용된다면 중복 제거를 생략할 수 있다.
중복을 고려한 시스템 설계
스트리밍 형의 메세지 배송 방식에서는 중간에 중복 제거 방식을 도입하지 않으면 중복 가능성이 있다고 생각하면 된다.
신뢰성이 중시되는 경우에는 스트리밍 형의 메세지 배송을 피하는 것이 좋다.
예를 들어, 과금 데이터같은 오차가 불허용 되는 경우 트랜잭션 처리를 지원하는 데이터베이스에 직접 애플리케이션이 기록해야한다. 그 후에 벌크 형의 데이터 전송을 함으로써 중복도 결손도 확실히 피해야한다.
3. 시계열 데이터의 최적화
스티밍형의 메세지 배송에서는 ‘메세지가 도착할 때까지의 시간 지연’ 이 문제다. 늦게 도달하는 데이터가 집계 속도에 미치는 영향을 정리한다.
프로세스 시간과 이벤트 시간
다음 두 시간의 차이가 성가신 문제를 일으킨다.
이벤트 시간
클라이언트 상에서 메시지가 생성된 시간. 데이터 분석의 대상은 주로 이벤트 시간프로세스 시간
서버가 처리하는 시간
프로세스 시간에 의한 분할과 문제점
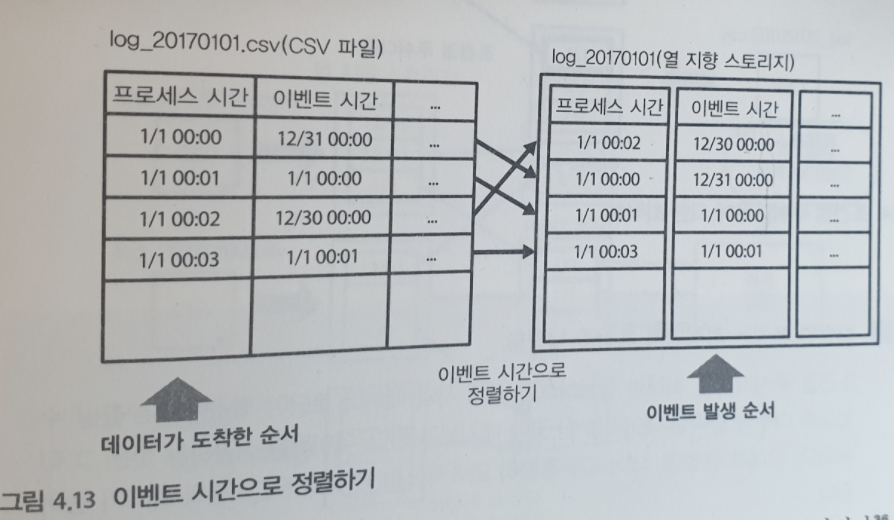
늦게 도달하는 데이터가 있다는 것은, 과거의 집계 결과가 매일 조금씩 바뀐다는 것을 의미한다. 보다 실제에 가까운 데이터를 얻기 위해서는 ‘이벤트 시간’ 보다 며칠 정도 지난 시점에서 집계해야한다.
분산 스토리지에 데이터를 넣는 단계에서는 이벤트 시간이 아니라 프로세스 시간 사용하는 것이 보통이다.
예를 들어, 2017년 1월 1일에 도착한 데이터는 ‘20170101’ 과 같은 이름으로 지정한다. 그리고 그 파일에는 이벤트 시간으로 보면 다수의 과거 데이터가 포함된 상태다. 다음 그림과 같다.

이 상태에서 과거 특정 일에 발생한 이벤트를 집계하고 싶다고 하자. 예를 들어, 1월 1일에 발생한 이벤트면, 그 이후에 만들어진 모든 파일에 포함되어 있을 수 있다.
다수의 파일을 모두 검색하는 쿼리를 Full Scan 이라고 한다. 이것이 시스템의 부하를 높이는 요인이다.
시계열 인덱스 : 이벤트 시간에 의한 집계 효율화 01
이벤트 시간 취급을 효율화하기 위해 데이터를 정렬해보자.
이벤트 시간에 대해 인덱스 만들기
RDB 에서 익덴스를 만든것 처럼.
Cassandra 와 같은 시계열 인덱스 (time-series index) 에 대응하는 분산 데이터베이스를 이용하면 처음부터 이벤트 시간으로 된 테이블을 만들 수 있다.
시계열 인덱스를 사용하면, 매우 짧은 범위의 특정 시간에 맞춘 데이터 집계를 빠르게 실행할 수 있다.
정해진 시간에 발생한 이벤트를 조사하거나, 실시간 대시보드를 만드는 경우에 유용하다.열 지향 스토리지
장기간에 걸쳐 대량에 데이터를 집계하는 경우에는 분산 데이터베이스가 효율적이지 않다.
장기적인 데이터 분석에는 집계 효율이 높은 열지향 스토리지를 지속적으로 만들어야한다.
조건절 푸쉬다운 : 이벤트 시간에 의한 집계 효율화 02
매일 한 번씩 새로 도착한 데이터를 배치 처리로 변환해보자.
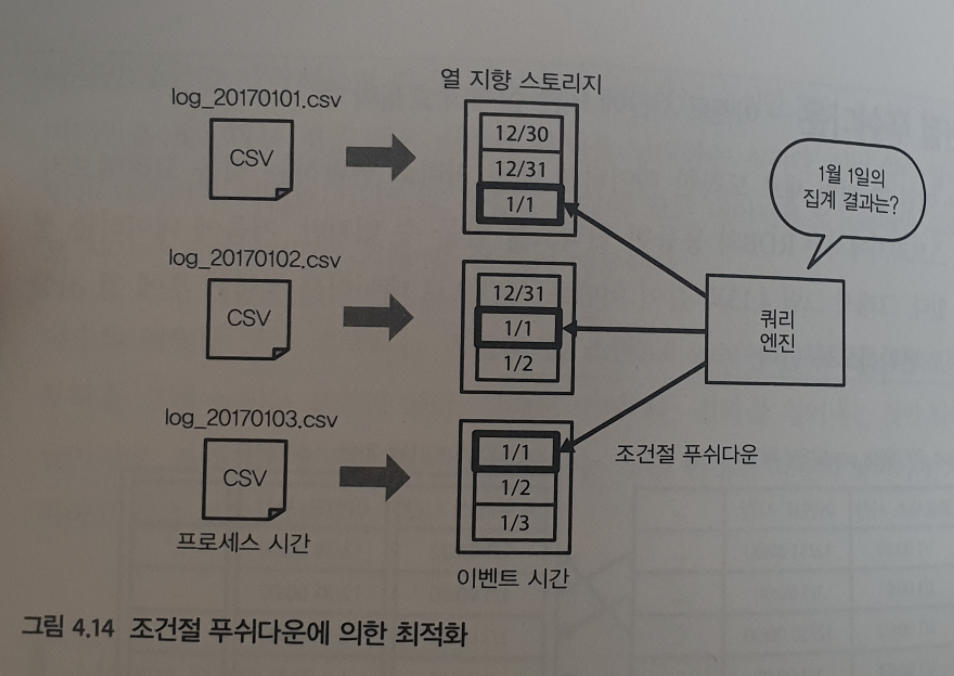
열 지향 스토리지에서는 RDB 와 동등한 인덱스를 만들 수 없지만, 처음에 데이터를 정렬할 수 있다. 그래서 다음 그림처럼, 이벤트 시간으로 데이터를 정렬하고 열지향 스토리지로 변환하자.
열 지향 스토리지는 ‘칼럼 단위의 통계 정보’ 를 이용해 최적화가 이뤄진다. 예를 들어, 시간이면 각 칼럼의 최솟값과 최댓값 등이 모든 파일에 메타 정보로 저장되어 있다. 그런 정보를 참고해 어떤 파일의 어떤 부분에 원하는 데이터가 포함되어 있는지 알 수 있다.
조건절 푸쉬 다운이란, 이 통계를 이용해 필요한 최소한의 데이터를 읽도록 최적화 하는 것이다. 열 지향 스토리지를 만들 때, 가급적 읽어 들이는 데이터 양을 최소화하기 위해 데이터를 정렬해서 조건절 푸쉬다운에 의한 최적화로 풀 스캔을 피한다.
이벤트 시간에 의한 분할
앞 장에서 테이블을 물리적으로 분리하는 테이블 파티셔닝을 설명했다. 그 중에서도 시간을 이용해 분할된 테이블을 시계열 테이블 이라고 한다. 여기에서는 다음 그림과 같이 이벤트 발생 시간을 파티션의 이름에 포함되도록 한다.
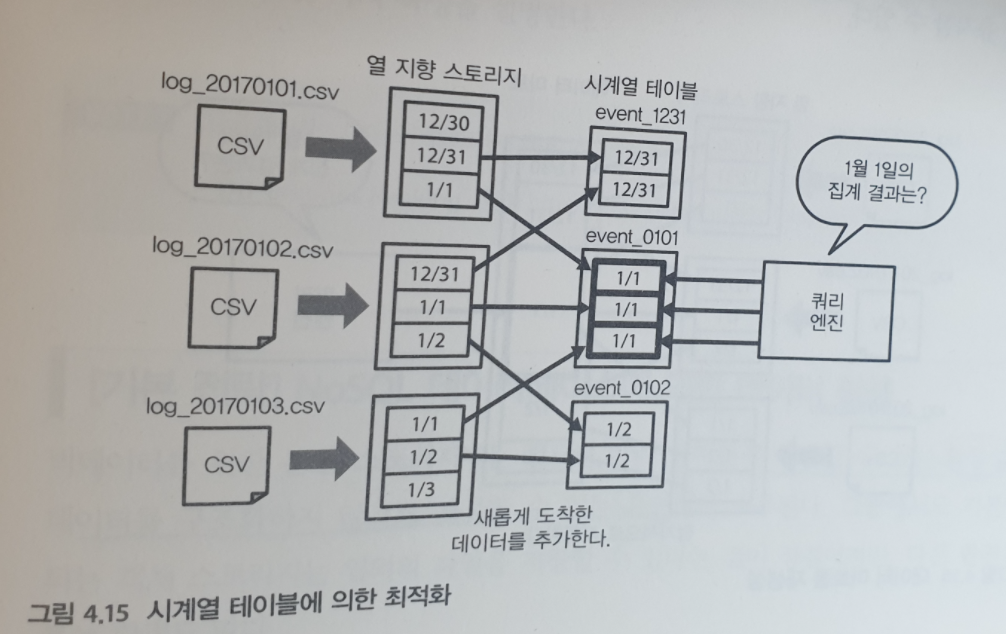
과거의 이벤트 시간을 갖는 데이터를 드물지만, 몇년에 걸쳐서 보내올 가능성이 있다. 따라서, 시계열 테이블을 구성하는 각 파티션에는 조금씩 데이터가 추가된다.
결과적으로, 분산 스토리지에는 대량의 작은 파일이 만들어지고 점차 쿼리의 성능이 악화된다. 그래서, 이벤트 시간으로부터 시계열 테이블을 만든다면
- 작은 데이터를 효율적으로 추가할 수 있는 데이터베이스를 사용하거나
- 너무 오래된 데이터는 버리는 아이디어가 필요하다.
데이터 마트를 이벤트 시간으로 정렬하기
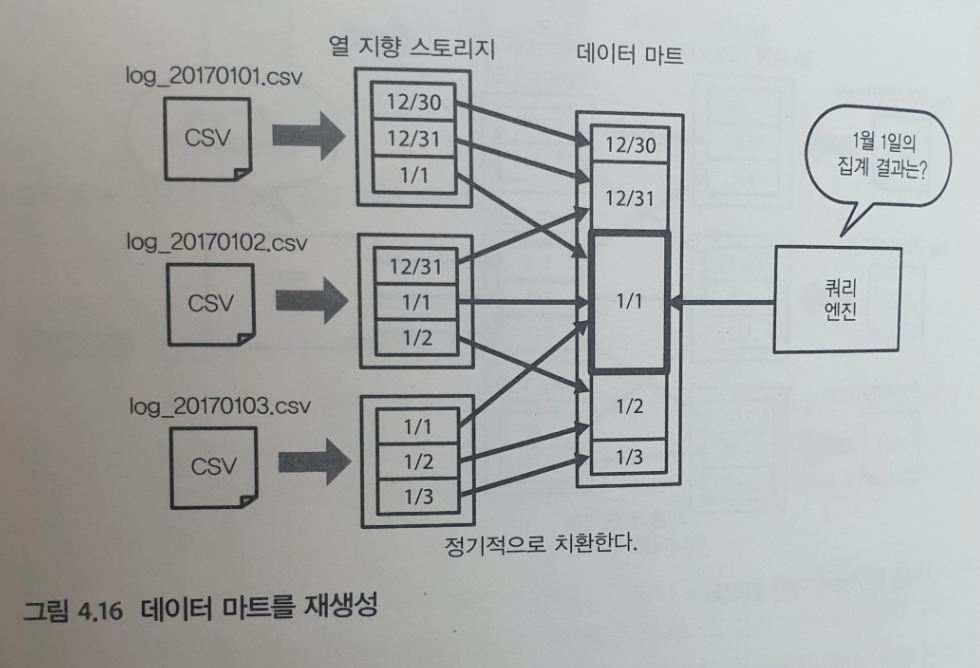
- 데이터 수집 단계에서는 이벤트 시간을 따지지 않고 프로세스 시간만을 사용하여 데이터를 저장한다.
- 그리고 데이터 마트를 만드는 단계에서 이벤트 시간에 의한 정렬을 한다.
그러면, 파일이 조각나는 일이 없고, 항상 최적의 데이터 마트를 유지할 수 있다.
4. 비구조화 데이터의 분산 스토리지
NoSQL 데이터베이스에 의한 데이터 활용
빅데이터를 위한 분산 스토리이지는, 다음이 요구된다.
확장성
필요에 따라 얼마든지 확장할 수 있어야한다.유연성
데이터를 구조화하지 않고도 저장할 수 있어야한다.
기본이 되는 객체 스토리지는,
장점
임의의 파일을 저장할 수 있다.단점
파일을 교체하기 어렵다. 일단 파일으 써넣으면 통째로 교체할 방법이 없다. 로그 파일처럼 나중에 변경할 일이 없는 것은 상관 없지만, 데이터베이스처럼 수시로 변경하는 용도는 적합하지 않다. 특히 중요한 데이터는 트랜잭션 처리가 가능한 데이터베이스에 기록해야한다.그리고, 객체 스토리지에 저장된 데이터를 집계할 수 있게 되기까지는 시간이 걸린다. 열지향 스토리지를 만듦으로써 집게는 고속화 되지만, 그 작성에 시간이 걸린다. 데이터를 기록하고 바로 활용할 경우 실시간 집계와 검색에 적합한 데이터 저장소가 필요하다.
객체 스토리지의 단점을 해결하기 위한 데이터 저장소를 일컬어 NoSQL 데이터베이스이다. NoSQL 데이터베이스의 예로,
- 분산 KVS
- 와이드 칼럼 스토어
- 도큐먼트 스토어
분산 KVS
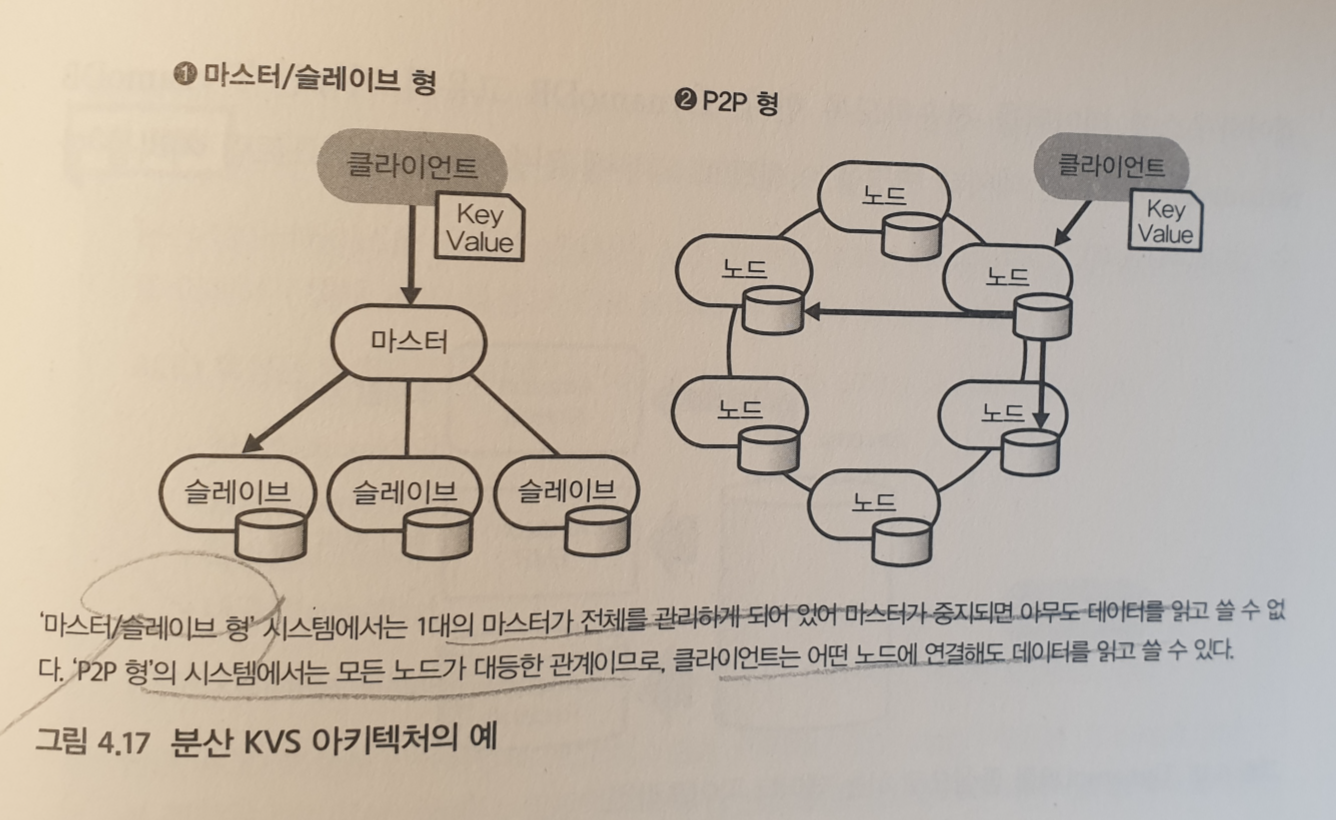
모든 데이터를 키값 쌍으로 저장하도록 설게된 데이터 저장소이다.
키가 정해지면, 그 값을 클러스터 내의 어느 노드에 배치할 것인지 결정한다. 이 구조에 의해 노드 간에 부하를 균등하게 분산하고 노드를 증감하는 것만으로 클러스터의 성능을 변경할 수 있다.
예를 들어, 아마존의 DynamoDB 가 있다.
분산 아키텍쳐
P2P 형의 분산 아키텍쳐를 가지고 있으며, 미리 설정한 초 단위의 요청 수에 따라 노드가 증감되는 특징이 있다. 따라서, 데이터의 읽기 및 쓰기에 지연이 발생하면 곤라한 애플리케이션에 유용하다.데이터 분석
DynamoDB 데이터를 분석하려면, 아마존 EMR, Redshift 등과 결합하여 Hive 에 의한 배치 처리를 실행하거나 데이터 웨어하우스에 데이터를 전송하도록 한다.스트림 처리
DynamoDB 고유 기능인 DynamoDB Streams 를 상요하면 데이터 변경을 이벤트로 외부에 전송해 실시간 스트림 처리가 가능하다.
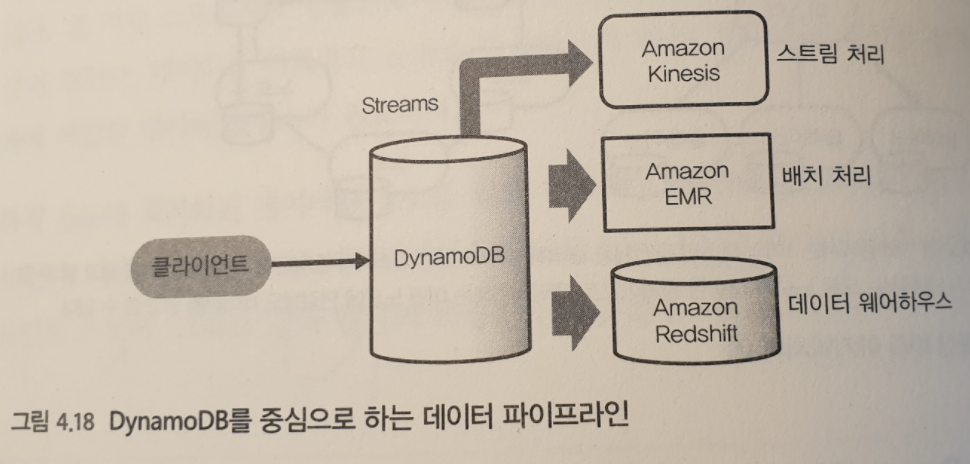
일반적으로 NoSQL 데이터베이스는 애플리케이션에서 처음에 데이터를 기록하는 장소로 이용된다. NoSQL 데이터베이스 자체는 대량의 데이터를 집계하는 기능이 없는 것이 많아 데이터 분석을 위해서는 외부로 데이터를 추출해야한다.
단, RDB 등과 비교하면 읽기 성능이 높기 때문에 쿼리 엔진에서 접속해도 성능상의 문제가 발생하기 어렵다. 그래서 애드 혹 분석에서는 데이터를 복사하지 않고 필요시에 직접 연결해서 사용할 수 있다.
[기초지식] ACID 특성과 CAP 정리
ACID 란 트랜잭션 4 가지 성질로 ‘원시성, 일관성, 독립성, 내구성’이다. 일반적인 RDB 는 이것을 충족하고 있어서 신뢰성있는 트랜잭션 처리를 하고 있다.
하지만, ACID 를 만족하면서 분산 시스템을 구축하기는 어려워서 CAP 정리가 나왔다. 일반적으로 분산 시스템에서는 다음 세가지를 동시에 충족시킬 수 없어 하나가 희생될 수 있다.
CAP 정리 : 일관성, 가용성, 분단내성
NoSQL 데이터베이스의 일부는 CAP 정리의 일관성이나 가용성 중 하나를 선택한다. 즉, 일관성을 우선하고 가용성을 포기하면 단시간의 장애 발생을 수용하는 것이고, 가용성을 우선하고 일관성을 포기하는 것은 오래된 데이터를 읽을 수 있는 것이다. 그 중에서도 결과 일관성이란, ‘써 넣은 데이터를 바로 읽을 수 있다고는 말할 수없다’ 이다.
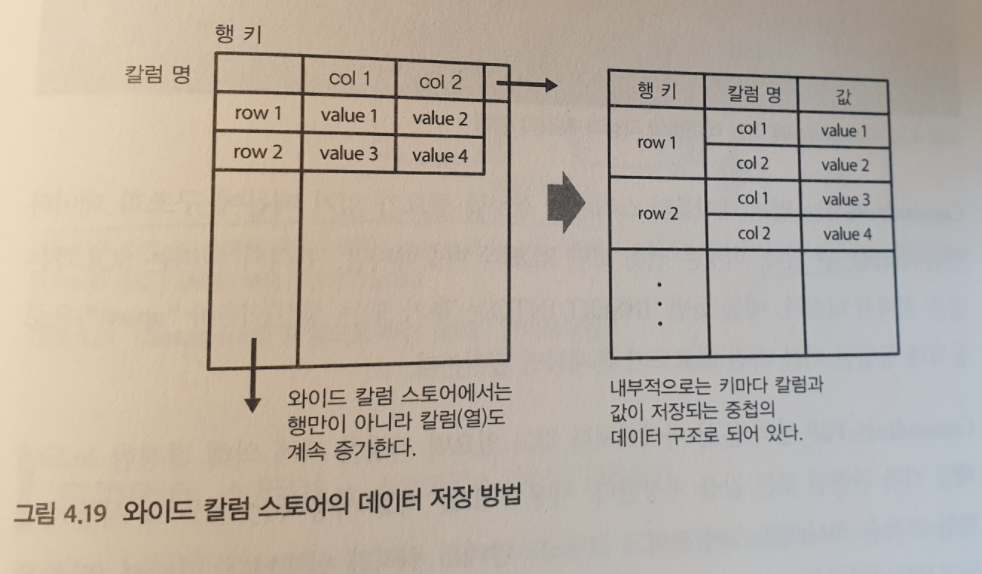
와이드 칼럼 스토어
KVS 를 발전시켜, 2개 이상의 임의의 키에 데이터를 저장할 수 있도록 한 것이다.
ex ) Google Cloud Bigtable, Apache HBase, Apache Cassandra
하나의 테이블에 가로와 세로의 2차원에 데이터를 쓸 수 있도록 한 것이 특징이다.
예를 들어, Apache Cassandra 를 살펴보자.
CQL
내부적으로 데이터 저장소로 와이드 칼럼 스토어를이용하면서, CQL 이라는 높은 수준의 쿼리 언어가 구현되어 있다.
SQL 동일한 감각으로 테이블을 조작할 수 있다구조화된 데이터만 취급
먼저 테이블의 스키마를 결정할 필요가 있기 때문에, 구조화 데이터만 취급한다.분산 아키텍쳐
P2P 형의 분산 아키텍쳐를 갖고 있으며, 지정한 키에 의해 결정한 노드에 해당 키와 관련된 모든 값을 저장한다.
사용자 id 를 키로 사용하는 경우, 그 사용자에 대한 기록은 하나의 노드에 모이고 그 노드 안에서 쿼리가 실행된다.
따라서 다수의 독립적인 키가 있는 경우에 처리를 잘 분산 할 수 있다.
와이드 칼럼 스토어에도 데이터를 집계하는 데는 적합하지 않다. 집계를 위해서는 분산된 모든 노드에서 데이터를 모아야하기 때문이다. Hive, Presto, Spark 등의 쿼리 엔진을 이용해 데이터를 추출해야한다.
도큐먼트 스토어
와이드 칼럼 스토어가 성능 향상을 목표로 하는 반면, 도큐먼트 스토어는 데이터 처리읭 유연성을 목적으로 한다. 구체적으로는, JSON 처럼 복잡한 스키마리스 에이터를 그대로의 형태로 저장하고 쿼리를 실행할 수 있도록 한다.
물론 간단한 분산 KVS도 JSON 텍스트로 저장할 수 있다. 하지만, 그에 대한 복작한 쿼리를 실행할 수 없다.
도큐먼트 스토어의 장점은, 스키마를 정하지 안혹 데이터 처리를 할수 잇다는 것이다. 그래서 외부에서 들여온 데이터를 저장하는데 특히 적합하다.
예를 들어, MongoDB를 살펴보자. 여러 노드에 데이터를 분산할 수 있지만, 그 자체는 대량의 데이터를 집계하는데 적합하지 않다. 데이터 분석이 목정니 경우 역시 쿼리 엔진으로부터 접속하는 등 데이터를 추출할 필요가 있다.
검색 엔진
NoSQL 데이터베이스와는 성격이 다르지만, 저장된 데이터를 쿼리로 찾아낸다는 점에서는 유사한 부분이 있다. 특히 텍스트 데이터 및 스키마리스 데이터를 집계하는데 자주 사용된다.
검색 엔진의 특징은 텍스트 데이터를 전문 검색하기 위해 역색인을 만드는 부분이다. 따라서, 기록하는 시스템 부하 및 디스크 소비량은 커지지만, 키워드 검색이 고속화된다.
검색 엔진은 텍스트 데이터를 검색하기 위해 역색인을 만든다. 즉, 텍스트에 포함된 단어를 분해하고 어떤 단어가 어떤 레코드에 포함되어 있는가에 대한 인덱스를 먼저 만들어서 검색을 고속화한다.
예전이라면, 검색 엔진을 사용하지 않고도 전체 스캔을 하는것은 생각할 수 없었지만, 빅데이터 기술의 발전으로 그것도 가능하다. 예를들어, Google BigQuery 를 사용하면 대량의 계산 자원을 이용해 몇 초 만에 빅데이터의 전체 스캔이 가능하다. 쿼리를 실행시킬 때마다 모든 데이터를 로드하기 때문에 매우 비효율적이지만, 실행 빈도가 높지 않다면 문제가 없다.
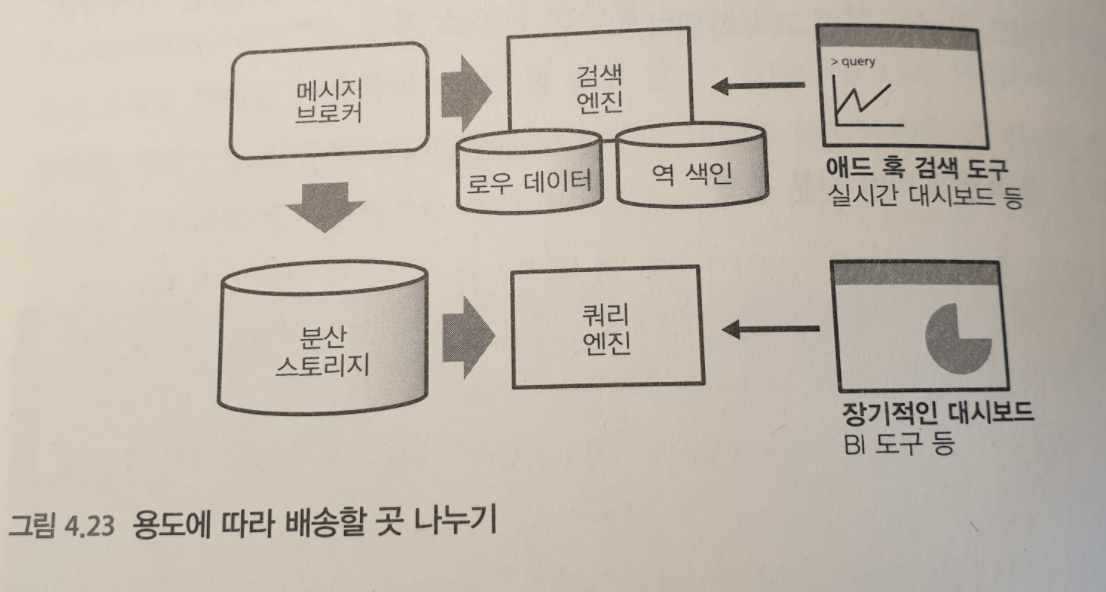
검색엔진은 데이터의 집계에 적합하며, 민첩성이 요구되는 용도에 최근의 데이터를 보기위해 사용된다. 장기적인 데이터를 축적하기 보다, 실시간 집계 시스템의 읠부로 이용된다. 예를 들어, 메세지가 배송된 데이터를 분산 스토리지에 저장하고, 같은 데이터를 검색 엔진에 전송해 실시간성이 높은 데이터 처리를 위해 활용된다.
에를들어, Elasticsserach 가 있다. 임의의 JSON 데이터를 저장할수 있어서 도큐먼트 스토어와 비슷하지만, 아무것도 지정하지 않으면ㅌ 모든필드에 색인이 만들어진다.
Splunk 도 있다. 자신하는 분야는 비정형 데이터로, 주로 웹서버나 네트워키 기기 등으로부터 출력되는 로그 파일이나 JSON 파일으 다루어 텍스트 처리를 해야만 분석할 수 잇는 데이터이다.에를 들어, 검색 엔진이므로 키워드를 입력하면 그것을 포함하는 로그를 찾을 수 있다. 최근의 데이터부터 순서대로 검색되므로 매일 발생하는 각종 이벤트를 빠르게 찾거나 보고서 작성에 유용하다.
빅데이터를 지탱하는 기술 <니시다 케이스케>