[카프카] 8장_카프카 스트림즈 API
카프카 스트림즈 API 를 통해 스트림을 처리하는 방법을 정리한다.
기본 개념
스트림 프로세싱과 배치 프로세싱
오늘날 데이터 분석 시스템은 스트림 처리 시스템과 배치 처리 시스템을 모두 갖추어서 실시간과 정확성을 보장한다.
스트림 프로세싱
데이터들이 지속적으로 유입되고 나가는 과정에서 데이터에 대한 분석이나 질의를 수행하는 것이다.
데이터가 분석 시스템이나 프로그램에 도달하자마자 처리를 해서 실시간 분석이라고도 한다.배치 처리
이미 저장된 데이터를 기반으로 분석이나 질의를 수행하고 특정 시간에 처리하는 것이다.
스티름 프로세싱의 장점은,
- 이벤트 발생, 분석, 조치에 지연시간이 없기 때문에,
최신의 데이터를 반영한다. - 데이터 저장 후 분석을 하지 않으므로, 정적 분석보다
더 많은 데이터를 분석할 수 있다. - 시간에 따라
지속적으로 유입되는 데이터 분석에 최적화되어 있다. - 대규모 공유 데이터베이스에 대한 요구를 줄일 수 있어
인프라에 독립적으로 수행될 수 있다.
상태 기반 스트림 처리, 무상태 스트림 처리
상태 기반 스트림 처리
이전 스트림을 처리한 결과를 참조하는 방식의 처리이다.
애플리케이션에서 각각의 이벤트를 처리하고 결과를 저장할 상태 저장소가 필요하다.무상태 스트림 처리
이전 스트림의 처리 결과와 관계 없이,현재 애플리케이션에 도달한 스트림만을 기준으로 처리한다.
카프카 스트림즈의 특징과 개념
카프카 스트림즈는 카프카에 저장된 데이터를 처리하고 분석하기 위해 개발된 클라이언트 라이브러리이다.
카프카 스트림즈의 특징은,
- 간단하고 가벼운 클라이언트 라이브러리이다.
- 시스템이나 카프카에 대한 의존성이 없다.
- 이중화된 로컬 상태 저장소를 지원한다.
- 카프카 브로커나 클라이언트에 장애가 생겨도, 스트림에 대해선 한 번만 처리되도록 보장한다.
- 한 번에 한 레코드만 처리한다.
- 고수준의 스트림 DSL 를 지원하고, 저수준의 프로세싱 API 도 제공한다.
카프카 스트림즈는 스트림 처리를 하는 프로세서들이 서로 연결되어 항상 Topology 를 만들어 처리하는 API 이다.
다음 그림은 카프카 스트림즈 프로세스 토폴리지의 예이다.
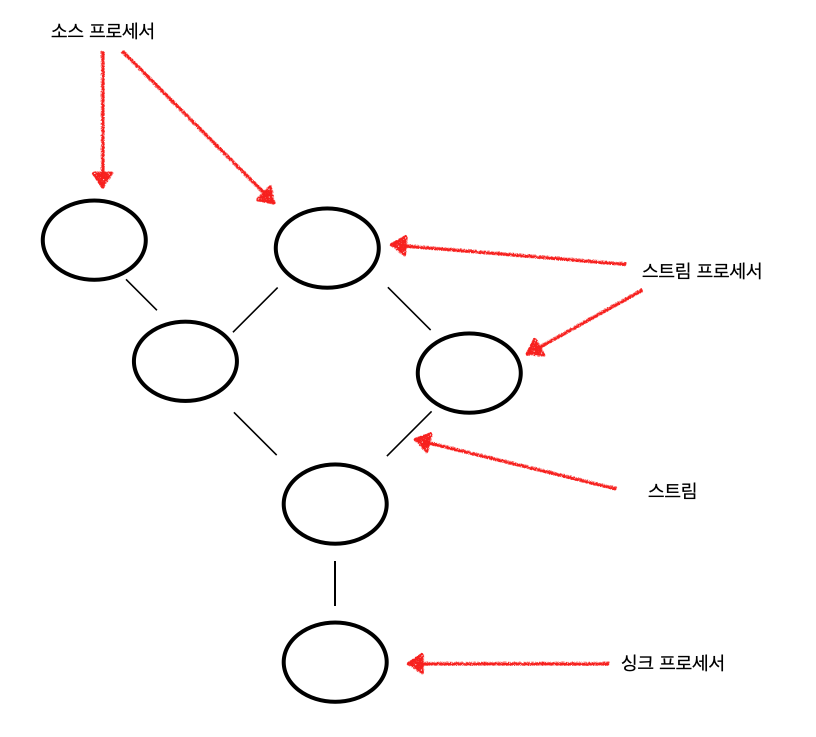
프로세서 토폴리지 중에는 특별한 프로세서가 있다.
소스 프로세서
위 쪽에 연결된 프로세서가 없는 프로세서이다.
하나 이상의 카프카 토픽에서 데이터 레코드를 읽어 아래 쪽 프로세서에 전달한다.싱크 프로세서
아래 쪽에 연결된 프로세서가 없는 프로세서이다.
상위 프로세서로부터 받은 데이터 레코드를 특정 토픽에 저장한다.
카프카 스트림즈는 이와 같은 프로세서들을 만드는 2 가지 방법을 제공한다.
카프카 스트림즈 DSL 에서 데이터 처리를 할 때 공통적으로 필요한 데이터 프로세싱 메서드를 제공
ex) map, filter, join, aggregations프로세서 API 를 제공해서 저수준의 처리를 직접할 수 있게 하는 것이다.
카프카 스트림즈 아키텍처
카프카 스트림즈에 들어오는 데이터는 카프카 토픽의 메세지이다.
카프카 토픽과 스트림의 관계는,
- 각 스트림 파티션은 카프카의 토픽 파티션에 저장된 졍렬된 메세지이다.
- 스트림의 데이터 레코드는 카프카 해당 토픽의 메세지이다.
- 데이터 레코드의 키를 통해 다음 스트림으로 전달된다.
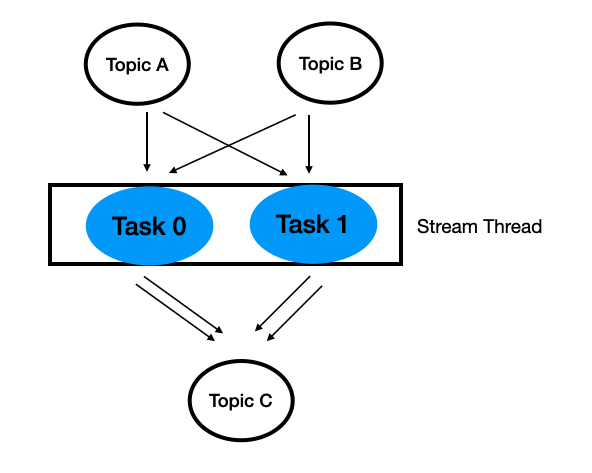
카프카 스트림즈는 입력 스트림의 파티션 개수만큼 태스크를 생성한다.
각 태스크에는 입력 스트림, 즉 카프카 토픽 파티션들이 할당된다.
이것은 한번 정해지면 입력 토픽의 파티션이 변하지 않는한 변하지 않는다.
카프카 스트림즈는 사용자가 스레드의 개수를 지정할 수 있게 한다.
1개의 스레드는 1개 이상의 테스크를 처리할 수 있다.
다음 그림은 1개의 스레드에서 2개의 테스크가 수행되는 모습이다.
카프카, 데이터 플랫폼의 최강자 <고승범, 공용준>