[빅데이터] 6장_일괄처리 계층
데이터 시스템의 목적은, 데이터에 관한 임의의 질문에 응답하는 것이다. 데이터 집합 전체를 입력으로 받는 함수는 실행 시간이 매우 오래 걸리므로, 질의의 빠르게 응답할 수 있는 다른 전략이 필요하다.
람다 아키텍쳐에서 일괄처리 계층은, 마스터 데이터 집합으로부터 일괄처리 뷰를 사전 계산해서 질의가 빠르게 처리될 수 있도록 한다.
6.1 일괄 처리 구실로 좋은 예제
각 예제는 마스터 데이터 집합 전체를 입력 받는 함수로, 질의를 어떻게 실행하는지 보여준다. 이 예제는 질의 요청이 들어올 때 즉석으로 실행하는 대신, 사전 계산을 사용하도록 구현이 변경될 것이다.
6.1.1 시간대별 페이지뷰
지정한 시간대에서 발생한 특정 URL 에 대한 페이지뷰 수의 총계를 구하는 것.
6.1.2 성별 추로
이름 데이터 집합 레코드를 사용해서 개인의 성별 추론.
6.1.3 영향력 지수
소셜 네트워크에서 개인의 영향력 지수를 구함.
6.2 일괄 처리 계층에서 계산을 수행하기
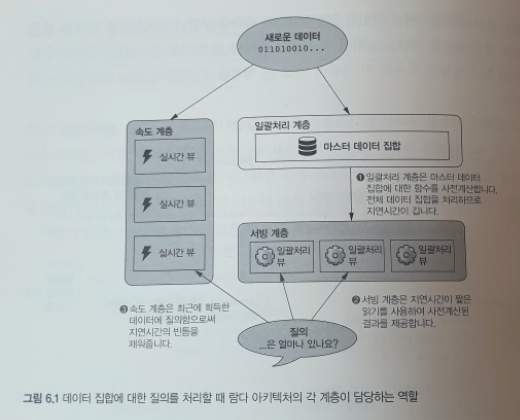
- 일괄 처리 계층은, 마스터 데이터 집합에 대한 함수를 실행해서 일괄 처리 뷰라고 불리는 중간 결과를 사전 계산한다.
- 일괄 처리 뷰는 서빙 계층에 로딩되고, 서빙 계층은 데이터에 빨리 접근할 수 있도록 이것에 대한 색인을 만들어둔다.
- 속도 계층은 일괄 처리 계층의 지연시간이 높은 것을 보완한다. 아직 일괄처리 뷰료 사전 계산 되지 않은 데이터에 대해 지연 시간이 낮은 갱신을 실행하는 것이다.
- 질의는 서빙 계층 뷰와 속도 계층 뷰의 처리 결과를 합쳐서 완료된다.
람다 아키텍쳐의 핵심은, 어떤 질의의 대해서도 일괄 처리 계층에서 데이터를 사전계산하여 서빙 계층에서 신속하게 처리할 수 있도록 할 수 있다는 것이다.
모든 질의를 사전계산할 수는 없다. 그 대신, 다음 그림처럼 중간 결과를 사전 계산하고 그 결과들을 사용해서 질의를 즉석으로 처리할 수 있다.
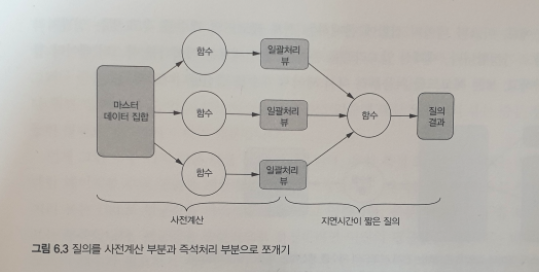
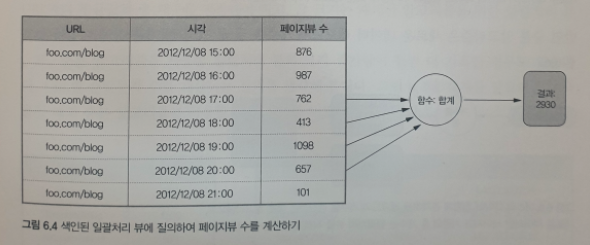
시간대별 페이지뷰 질의 예제에 대해 중관 결과를 사전 계산한다면, URL 개개마다 모든 시각에 대한 페이지뷰를 사전계산 해두는 것이다. 질의 처리를 완료하려면 색인에서 지정한 범위에 속하는 모든 시각에 대한 페이지뷰 수를 얻어서 그 결과를 합치면 된다.
빅데이터, 람다 아키텍처로 알아보는 실시간 빅데이터 구축의 핵심 원리와 기법 <네이선 마츠, 제임스 워렌>