Collection Framework - HashSet
Collection Framework 의 인터페이스 구조는 다음과 같다.
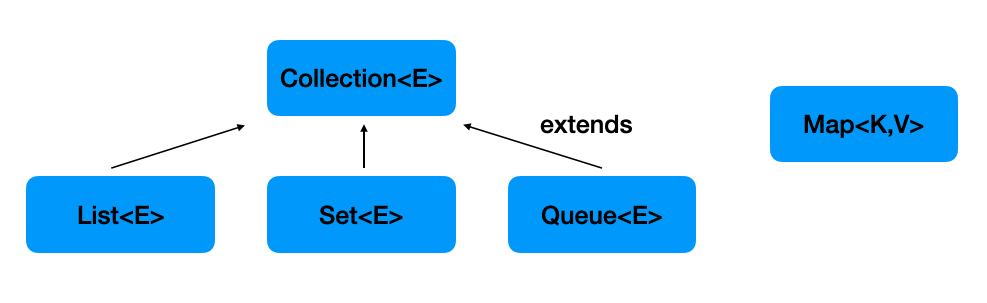
여기서, Set 인터페이스를 구현하는 클래스로는 HashSet, TreeSet 이 있다.
HashSet 클래스를 정리해보자.
1. Set 인터페이스
Set 인터페이스를 구현하는 클래스는 다음 특징을 가진다.
- 데이터 저장 순서를 유지하지 않음
- 데이터의 중복 저장을 허용하지 않음
2. HashSet - 예시 01
HashSet 은 다음과 같이 사용할 수 있다.
1 |
|
출려 결과는 다음과 같다.
1 | A |
출력 결과를 보면,
- 데이터 저장 순서를 유지하지 않았고,
- 데이터 중복을 허용하지 않았다.
그런데, 어떻게 데이터 중복을 허용하지 않은걸까 ? 어떻게 동일한 데이터인지 아닌지를 구분한걸까 ?
3. HashSet - 예시 02
다음과 같이, int 형 변수 num 을 하나 가지는 클래스가 있다고 하자.
1 | public class MyNumber { |
그리고 다음과 같이 테스트해보자.
1 |
|
위와 같이, new MyNumber(2) 를 두 번 저장하지만, 위 테스트 코드는 통과한다.
데이터 중복을 허용하지 않는 HashSet 인데 왜 중복을 허용한걸까? 왜냐하면, MyNumber(2) 를 서로 다른 인스턴스로 간주했기 때문이다.
어떻게 서로 다른 인스턴스로 간주한걸까 ?
HashSet 은 해쉬 알고리즘을 적용해서 데이터를 저장하고 검색한다. 해쉬 알고리즘이 무엇인지 정리해보자.
3. Hash
다음과 같은 해쉬 알고리즘이 있다.
1 | num % 3 |
어떤 숫자를 3 으로 나눈 나머지가, 숫자 분류의 기준이 되는 것이다. (이 기준 값을 해쉬 값이라고 한다.)
예를 들어, 다음과 같이 6 개의 숫자고 있다고 하자.
1 | 3 5 7 10 1 2 |
위 숫자들에 해쉬 알고리즘을 적용하면 세 그룹으로 묶을 수 있다.
- 나머지 결과 == 0 –> 3
- 나머지 결과 == 1 –> 7, 10, 1
- 나머지 결과 == 2 -> 5, 2
이 때, 5 가 6 개 의 숫자 리스트에 존재하는지 어떻게 확인 할 수 있을까 ?
- 5 를 3 으로 나눈 나머지를 구한다. 2 이다.
- 그리고, 나머지 결과 == 2 인 그룹에서 5 가 존재하는지 찾는다.
위와 같은 순으로 5 가 존재하는지 찾으면, 검색의 대상이 줄어드는 것을 알 수 있다. 따라서, 검색 속도가 굉장히 빠르다.
위와 같은 해쉬 알고리즘을 적용하는 HashSet 은 다음과 같이 중복 데이터 여부를 확인한다.
- Object 클래스의 hashCode 메서드 반환 값으로 해쉬 값 결정
- Object 클래스의 equals 메서드 반환 값으로 내용 비교
위 두 메서드를 오버라이딩 하지 않으면, 기본적으로
- hashCode 메서드는,
인스턴스가 다르면 내용에 상관 없이 다른 해쉬 값을 반환하고 - equals 메서드는, 내용 비교가 아니라
참조 값 비교만하도록 정의되어 있다.
3. 결과
String 을 저장한 예시 01 에서는, String 클래스가 위 두 메서드를 오버라이딩하고 있기 때문에, 중복 데이터인 여부를 판단할 수 있었던 것이다.
MyNumber 를 저장한 예시 02 에서는 위 두 메서드를 오버라이딩하지 않았다. 그래서,
- new MyNumber(2) 를 각각 서로 다른 인스턴스로 보고 서로 다른 해쉬 값을 반환했고,
- 내용인 2를 비교한 것이 아니라, 참조 값 비교만 한 것이다.
그래서, new MyNumber(2) 를 동일한 데이터로 간주하기 위해 오버라이딩 해보자.
1 | public class MyNumber { |
그러면, 아래 테스트 코드는 성공한다.
1 |
|
난 정말 JAVA 를 공부한적이 없다구요 <윤성우>