쿠버네티스 오브젝트
Pod / Replica Set / Service / Deployment 오브젝트를 정리한다.
쿠버네티스의 고유 특징
모든 리소스는 오브젝트 형태로 관리된다.
컨테이너의 집합 (Pods), 컨테이너의 집합을 관리하는 컨트롤러 (Replica Set), 사용자 (Service Account), 노드 (Node) … 등 하나의 오브젝트로 관리된다.
쿠버네티스에서 사용할 수 있는 오브젝트는 아래 명령어로 확인 가능하다.
명령어를 사용할 수 있지만, YAML 파일을 더 많이 사용한다.
kubectl 이라는 명령어로 쿠버네티스를 사용할 수 있지만,
YAML 파일로 컨테이너 뿐만 아니라 모든 리소스 오브젝트들에 사용될 수 있다.
여러 개의 컴포넌트로 구성되어 있다.
쿠버네티스 노드는 마스터 노드와 워커 노드로 나뉘어 있다.
마스터 노드는 클러스터를 관리하는 역할을 하고, 워커 노드에는 애플리케이션 컨테이너가 생성된다.
쿠버네티스는 도커를 포함한 많은 컴포넌트들이 도커 컨테이너로서 실행된다. 예를 들어,
마스터 노드에는 kube-apiserver, kube-controller-manager, kube-schueduler, coreDNS 등이 실행된다.
그리고, kubelet 이라는 에이전트가 모든 노드에 실행된다.
kubelet 은 컨테이너의 생성/삭제 뿐만 아니라 마스터와 워커 노드 간 통신 역할을 담당한다.
쿠버네티스 입장에서, 도커 데몬 또한 하나의 컴포넌트이다.
도머 스웜 모드는 도커에 내장된 기능인 반면, 쿠버네티스는 그렇지 않다.
오히려, 쿠버네티스가 도커를 이용하는 방식이다.
Pod: 컨테이너를 다루는 기본 단위
도커 엔진에서는 기본 단위가 도커 컨테이너이고, 스웜 모드에서는 기본 단위가 여러 컨테이너로 구성된 서비스이다.
쿠버네티스에서는 컨테이너 애플리케이션을 배포하기 위한 기본 단위로, 포드라는 개념을 사용한다.
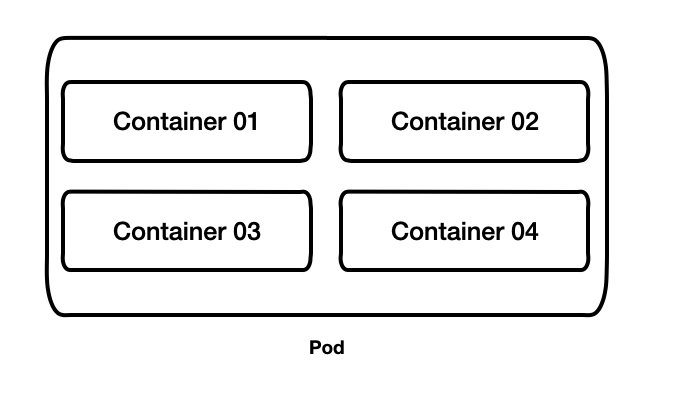
포드는 한 개이상의 컨테이너로 구성된 컨테이너의 집합이다.
Nginx 컨테이너로 구성된 Pod 를 생성하기 위해, nginx-pod.yaml 을 작성해보자.
1 | apiVersion: v1 |
위 YAML 파일은 아래 명령어로 쿠버네티스에 생성할 수 있다.
1 | kubectl apply -f nginx-pod.yaml |
생성된 포드의 IP 는 외부에서 접근할 수 없기 때문에, 클러스터 내부에서만 접근할 수 있다.
그래서, 클러스터의 노드 중 하나에 접속해서 Nginx 포드의 IP 로 HTTP 요청을 전송하면, Nginx 포드가 정상 실행중인 것을 알 수 있다.
Pod VS Docker Container
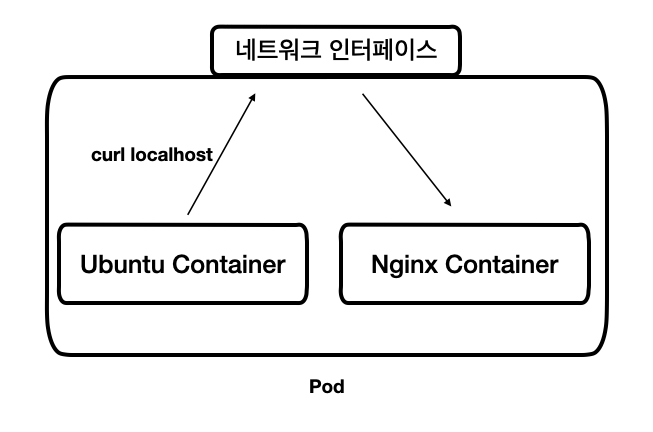
쿠버네티스는 도커 컨테이너가 아니라 왜 굳이 포드라는 새로운 개념을 사용하는걸까 ?
여러 리눅스 namespace 를 공유하는 여러 컨테이너들을 추상화된 집합으로 사용하기 위해서이다.
예를 들어, 포드 내의 컨테이너들은 리눅스 namespace 의 하나인, 네트워크 namespace 를 공유해서 사용하기 때문에 우분투 컨테이너에서 Nginx 서버를 실행하고 있지 않음에도 불구하고
우분투 컨테이너의 로컬호스트에서 Nginx 서버로 접근이 가능하다.
하나의 Pod 는 하나의 완전한 애플리케이션
Nginx 는 이 자체로 하나의 애플리케이션이다.
그런데, 프로세스나 로그를 수집해주는 프로세스가 Nginx 컨테이너와 함께 실행되어야 하는 경우가 있다.
이렇게 포드에 정의된 부가적인 컨테이너를 Sidecar 컨테이너라고 한다.
이 컨테이너는 포드 내의 다른 컨테이너와 네트워크 환경 등을 공유한다.
그래서, 포드에 포함된 컨테이너들은 모두 같은 워커 노드에서 함께 실행된다.
이러한 구조와 원리에 따라, 포드에 정의된 여러 컨테이너는 하나의 완전한 애플리케이션으로서 동작한다.
Replica Set: 일정 개수의 포드를 유지하는 컨트롤러
레플리카셋을 사용하는 이유는,
- 정해진 수의 동일한 포드가 항상 실행되도록 관리를 해주기 때문
- 노드 장애 등의 이유로, 포드를 사용할 수 없다면 다른 노드에서 포드를 다시 생성해 주기 때문
예를 들면,
- 동인한 Nginx 포드를 안정적으로 여러개 실행할 수 있고,
- 워커 노드에 장애가 생기더라도 정해진 개수의 포드를 유지할 수 있다.
Replica Set 사용
Nginx 포드를 생성하는 래플리카셋을 만들기 위해, replicaset-nginx.yaml 파일을 작성하자.
1 | apiVersion: apps/v1 |
그리고, 아래 명령어로 레플리카셋을 생성한다.
1 | kubectl apply -f replicaset-nginx.yaml |
만약에, 레플리카셋에 정의된 포드 개수를 4 개로 늘리고 싶으면,
이미 생성된 레플리카셋을 삭제하고 다시 생성할 필요가 없다.
왜냐하면, 쿠버네티스에는 이미 생성된 리소스의 속성을 변경하는 기능을 제공하기 때문이다.
위 YAML 파일의 spec.replicas 를 4로 설정한뒤에 다시 kubetl apply ~ 명령을 실행하면 된다.
Replica Set 동작 원리
레플리카셋과 포드는, Label Selector 를 이용해 연결된다.
레플리카셋은 spec.selector.matchLabel 에 정의된 라벨을 통해 생성해야할 포드를 찾는다.
위 YAML 파일의 경우에,
- “app: my-nginx-pods-label” 라벨을 가지는 포드의 개수가 replicas 항목에 정의된 숫자인 3 개와 일치하지 않으면
- 포드를 정의하는 template 항목 내용대로 포드를 생성한다.
핵심은, 레플리카셋의 목적이 일정 개수의 포드를 유지하는 것 이라는 것이다.
그래서,
- 현재 포드의 개수가 replicas 에 설정된 값보다 적으면 포드를 더 생성하고
- 많으면 포드를 삭제한다.
Deployment: 레플리카셋과 포드의 배포를 관리
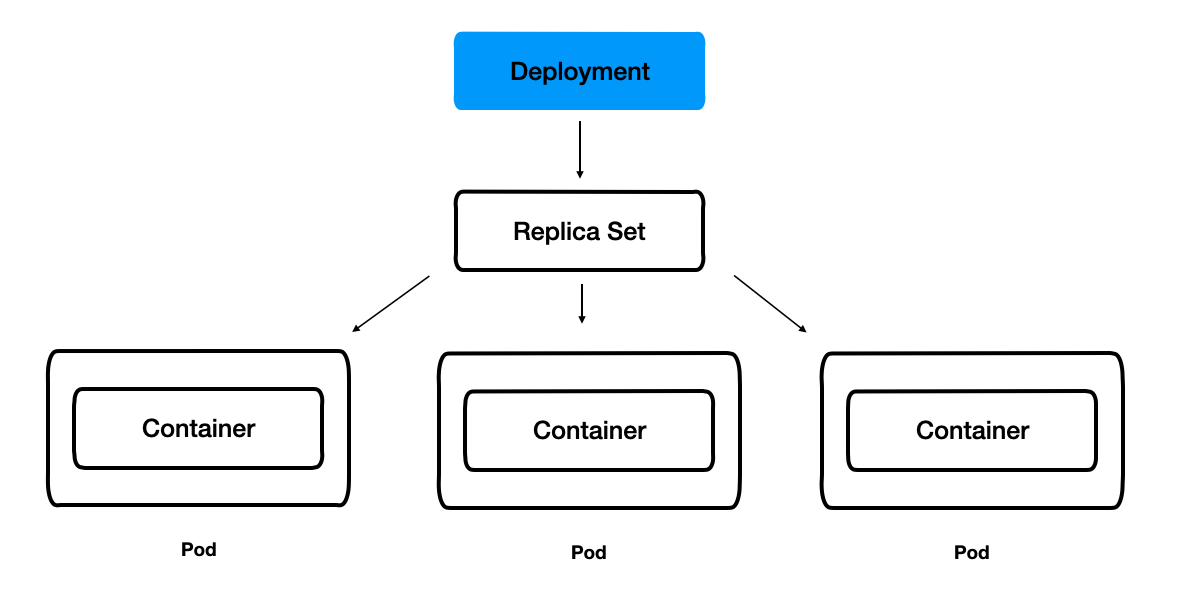
레플리카셋의 상위 오브젝트이다.
디플로이먼트를 생성하면, 해당 디폴로이먼트에 대응하는 레플리카셋도 함께 생성된다.
디플로이먼트 생성을 위해 deployment-nginx.yaml 파일을 작성하자.
1 | apiVersion: apps/v1 |
그리고 다음 명령어로 디플로이먼트를 생성한다.
1 | kubectl apply -f deployment-nginx.yaml |
Deployment 사용 이유
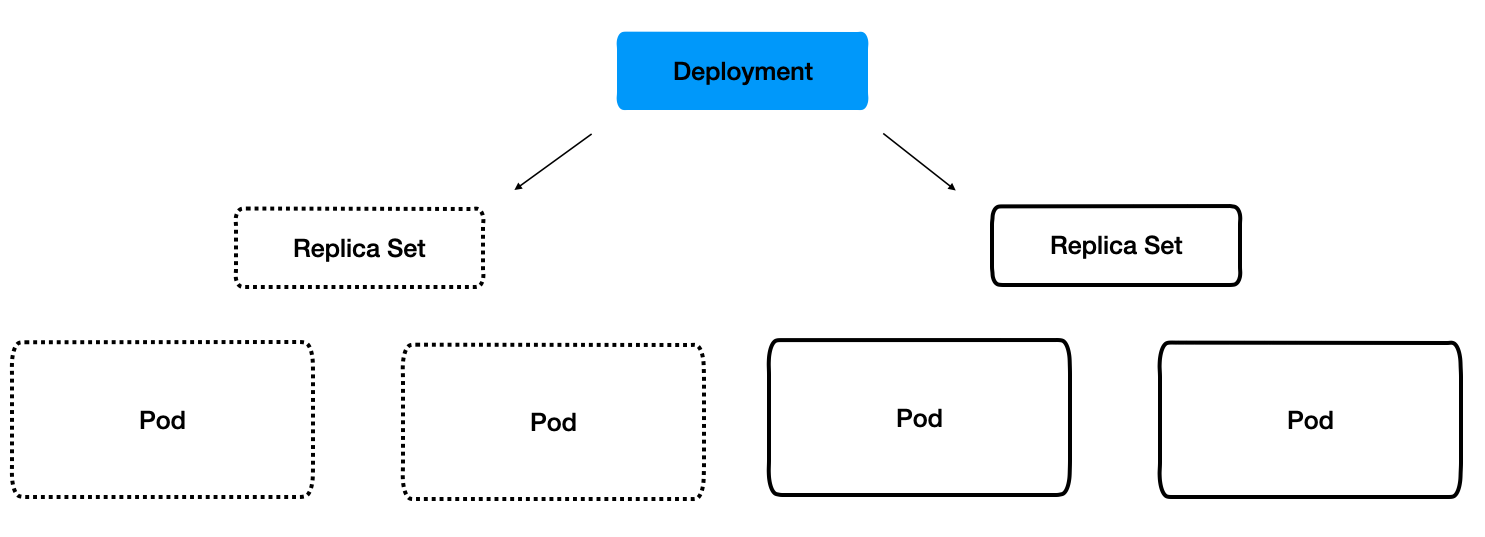
레플리카셋을 그대로 사용하지 않고, 왜 굳이 상위 개념을 도입해서 사용하는걸까 ?
애플리케이션의 업데이트와 배포를 편하게 하기 위해서이다.
- 애플리케이션을 업데이트할 때, 레플리카셋의 변경 사항을 저장하는 revision 을 남겨 롤백을 가능하게 하고,
- 무중단 서비스를 위해 포드의 롤링 업데이트 전략을 지정할수 있다.
예를 들어, 애플리케이션 버젼을 업데이트하기 위해 포드의 이미지를 변경해보자.
아래 명령어로,
포드 탬플릿에 정의된 containers 항목의 nginx 라는 이름을 가진 컨테이너의 이미지를 nginx:1.11 로 변경하자.
1 | kubectl set image deployment my-nginx-delpoyment nginx=nginx:1.11 |
그러면,
- 새롭게 포드들이 3 개 생성이 되고
- 새로운 replicaset 이 생성된다.
그리고, 이전 버전의 레플리카셋이 삭제되지 않고 남아있다.
즉, 디플로이먼트는 포드의 정보가 변경되어 업데이트가 발생할 때, 이전의 정보를 리비전으로 보존한다.
Service: 포드를 연결하고 외부에 노출
서비스 오브젝트는,
- 여러 개의 포드에 쉽게 접근할 수 있도록 고유한 도메인 이름을 부여
- 여러 개의 포드에 접근할 때, 요청을 분산하는 로드 밸런서 기능 수행
- 포트를 외부에 노출
서비스의 종류는 세 가지가 있는데 하나하나 알아보자.
- ClusterIP Type
- NodePort Type
- LoadBalancer Type
ClusterIP
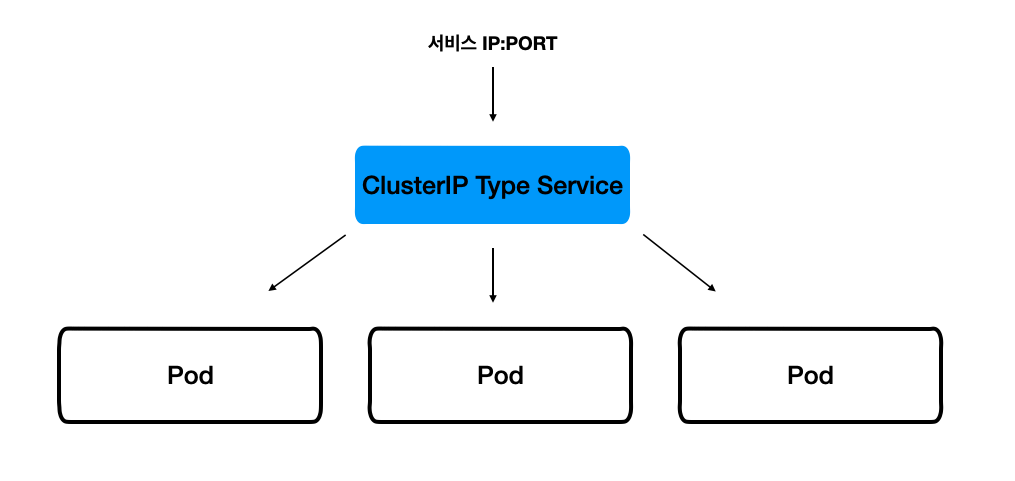
쿠버네티스 내부에서만 포드들에 접근할 때 사용한다.
아래 내용으로 hostname-svc-clusterip.yaml 파일을 작성하자.
1 | apiVersion: v1 |
그리고 서비스를 생성하자.
1 | kubectl apply -f hostname-svc-clusterip.yaml |
그러면 생성된 서비스의 IP:PORT 를 통해, 서비스와 연결된 여러 포드에 자동으로 요청이 분산된다.
NodePort
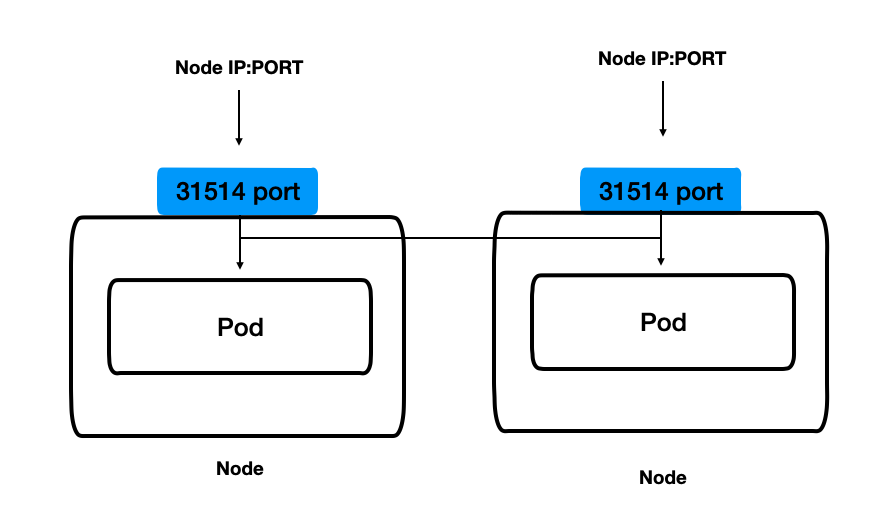
NodePort 타입의 서비스는, 클러스터 외부에서도 접근할 수 있다.
모든 노드의 특정 포트를 개방해 서비스에 접근하는 방식이다.
아래 내용으로 hostname-svc-nodeport.yaml 파일을 작성하자.
1 | apiVersion: v1 |
그리고 서비스를 생성하자.
1 | kubectl apply -f hostname-svc-nodeport.yaml |
그리고 서비스 목록을 확인해보면, PORT 항목에 31514 라는 숫자가 있다.
이것은, 모든 노드에 동일하게 접근할수 있는 포트이다.
즉,
- 외부에서 포드에 접근하기 위해 각 노드에 개방된 포트인 31514 로 요청을 전송
- 31514 포트로 들어온 요청은, 서비스와 연결된 포드 중 하나로 라우팅
LoadBalancer
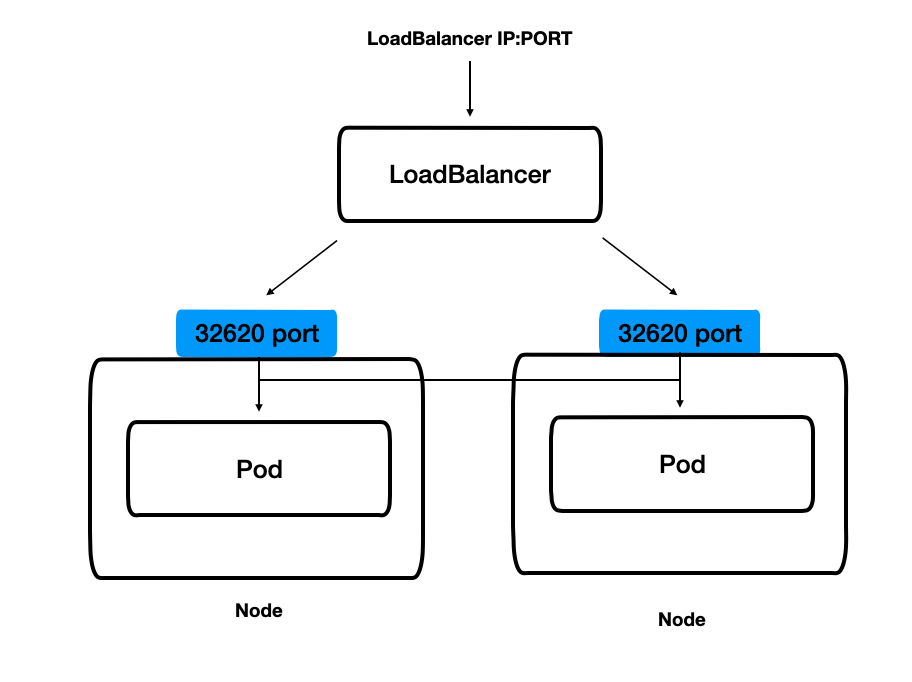
LoadBalancer 타입의 서비스 는 AWS, GCP 같은 클라우드 플랫폼 환경에서만 사용할 수 있다.
NodePort 를 사용할 때는, 각 노드의 IP 를 알아야 포드에 접근할 수 있었지만, LoadBalancer 타입의 서비스는 클라우드 플랫폼으로부터 도메인 이름과 IP 를 할당 받아 더 쉽게 포드에 접근 가능하다.
아래 대로, hostname-svc-lb.yaml 파일을 생성하자.
1 | apiVersion: v1 |
그리고 서비스를 생성하고 서비스 목록을 확인하면,
EXTERNAL-IP 항목이 있는데, 이 주소는 클라우드 플랫폼인 AWS 로부터 자동으로 할당된 것이다.
그리고 PORTS 항목에, 각 노드에 동일하게 접근할 수 있는 포트 번호를 부여받는다.
즉,
- LoadBalancer 타입의 서비스 가 생성되면서
- 모든 워커 노드는 포드에 접근할 수 있는 랜덤한 포트를 개방한다.
- 클라우드 플랫폼에서 생성된 로드 밸런서로 요청이 들어오면
- 쿠버네티스의 워커 노드 중에 하나로 전달되고
- 워커 노드로 전달된 요청은 포드 중 하나로 전달되어 처리된다.
시작하세요! 도커/쿠버네티스 <용찬호>