Spring Data JPA CRUD
Spring Data JPA 를 이용해서, repository 의 CRUD 를 직접 테스트한다.
Requirements
의존성을 다음과 같이 추가한다.
1 | dependencies { |
그리고, application.yml 에 다음과 같이 정의한다.
테스트 코드 실행시 수행된 SQL 을 확인하기 위함이다.
1 | spring: |
도서를 “생성/조회/수정/삭제” 하는 기능을 만들기 위해, Book 클래스를 정의하자.
1 | import javax.persistence.Entity; |
그리고 repository interface 를 정의하자.
1 | public interface BookRepository extends JpaRepository<Book, Long> { |
Create
Book 객체를 생성해서 저장하는 간단한 테스트 코드를 작성하자.
1 |
|
실행된 SQL 을 확인해보자.
예상했던 것과 같이, insert SQL 이 수행되었다.

Read
이제, Book 객체를 생성하고 저장한 뒤에 조회해보자.
1 |
|
결과는,

이상한 점이 있다. insert 를 한뒤에 왜 select 가 수행되는 걸까 ?
영속성 컨텍스트의 1차 캐쉬에 Book entity 가 남아있으면, select 수행이 필요없지 않나 ?
Update
이제, 저장한 Book 객체를 update 해보자.
1 |
|
결과는,

여기서도, 예상했던 것과 다르게 select 가 수행이 되었다.
영속성 컨텍스트의 1차 캐쉬에 Book entity 가 남아있으면, 1차 캐쉬의 Book entity 스냅샷과 변경된 Book entity 를 Dirty Checking 해서 update SQL 만 수행되어야 하는 것 아닌가 ?
Delete
마지막으로, 저장한 Book 객체를 delete 해본다.
1 |
|
여기서도, 예상했던 것과 다르게 select 가 수행이 되었다.

Transaction Range Persistence Context
위에서 보았듯이, 예상했던 것과 다르게 동작했던 원인을 파악해보자.
원인은, Spring 은 트랜잭션 범위의 영속성 컨텍스트 전략을 사용하기 때문이다.
즉,
- 트랜잭션을 시작할 때, 영속성 컨텍스트 생성하고
- 트랜잭션을 종료할 때, 영속성 컨텍스트 종료한다.
조회 테스트 코드를 다시 보자.
1 |
|
이 line 을 자세히 봐보자.
1 | Book savedBook = bookRepository.save(book); |
save 메서드를 따라가보면,
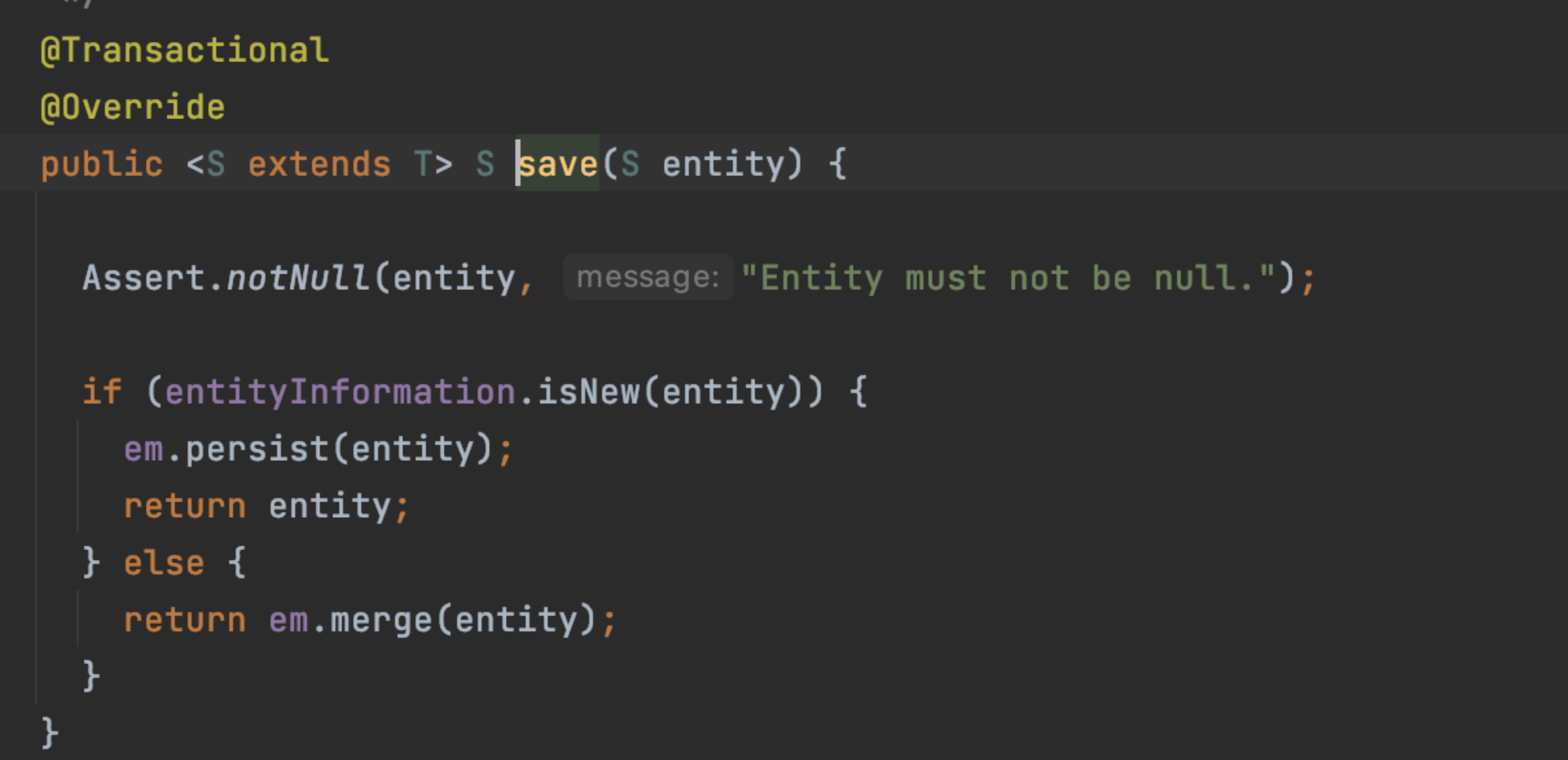
@Transactional 이 붙어있다. 즉,
- save 메서드를 시작하면서 트랜잭션을 시작하고 영속성 컨텍스트 생성한다.
- save 메서드가 종료되면서 트랜잭션을 종료하고 영속성 컨텍스트 종료한다.
즉,
영속성 컨텍스트는 save 메서드 내부에서만 유효했던 것이다.
findById() 에서는 Database 에서 조회하기 때문에, select SQL 이 수행되는 것이다.
Optimization
영속성 컨텍스트의 장점을 이용해서, 이 문제를 해결해보자.
결론은, read 테스트 메서드에서 영속성 컨텍스트를 유지하도록 하면 된다.
이를 위해, read 테스트 메서드에서 Transaction 을 시작하고 종료하도록 하면 된다.
즉, 아래와 같이 @Transactional 을 붙이는 것이다.
@Rollback 을 추가적으로 붙인 이유는, 테스트 메서드가 종료되어도 rollback 이 발생하지 않게 함으로써 실행된 SQL 을 확인하기 위함이다.
1 |
|
결과는, 기대했던바와 같이 추가적인 select 가 발생하지 않는다.
![]()
Update, Delete 도 위와 마찬가지로 해결된다. 이 부분은 생략한다.
Conclusion
Spring Data JPA 를 이용해서, repository 의 CRUD 를 직접 테스트해보았다.
결론은, Spring 은 트랜잭션 범위의 영속성 컨텍스트 전략을 사용한다는 것이다.
Spring Data JPA 를 사용한다면, Spring 에서 JPA 를 어떻게 활용하는지 정확히 이해하고 사용할 필요가 있다.