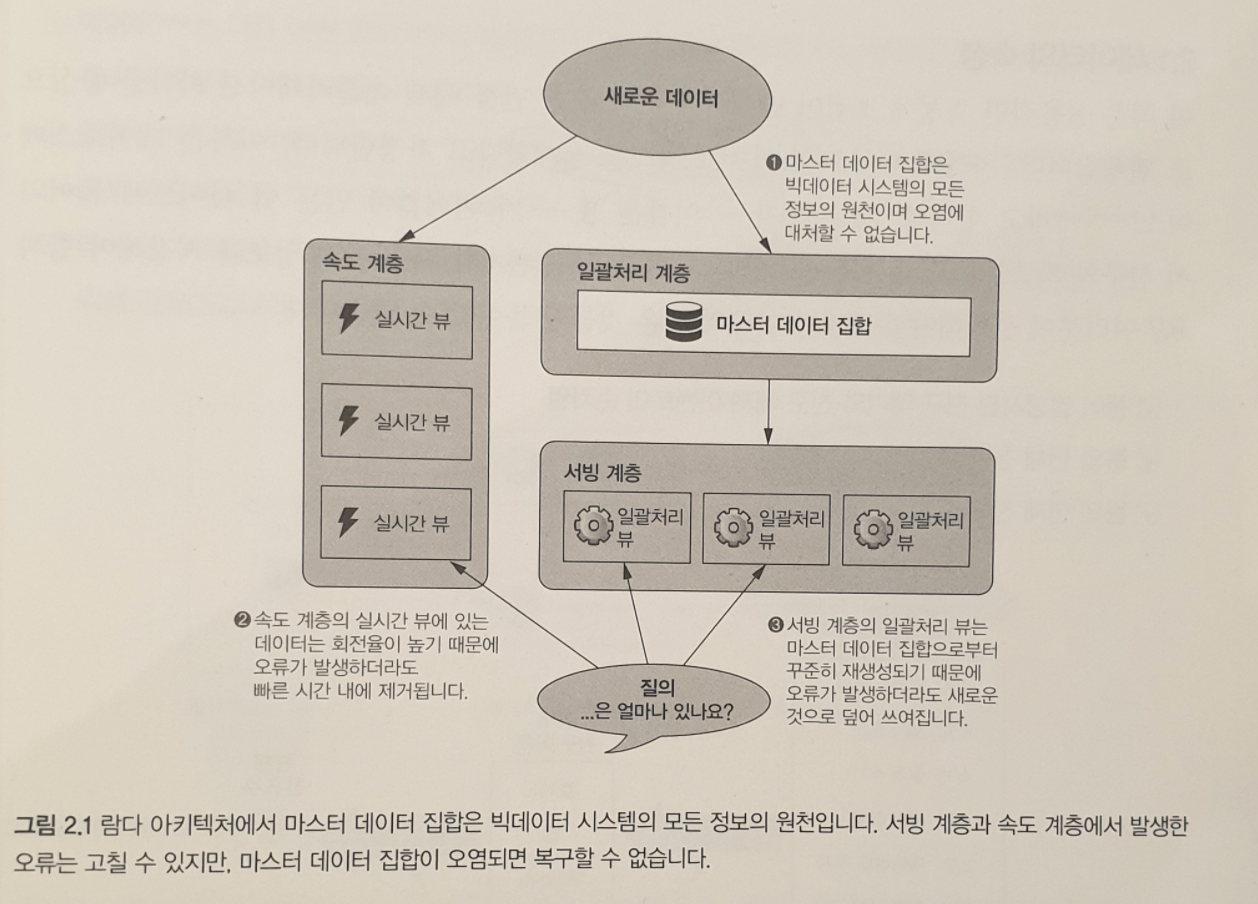
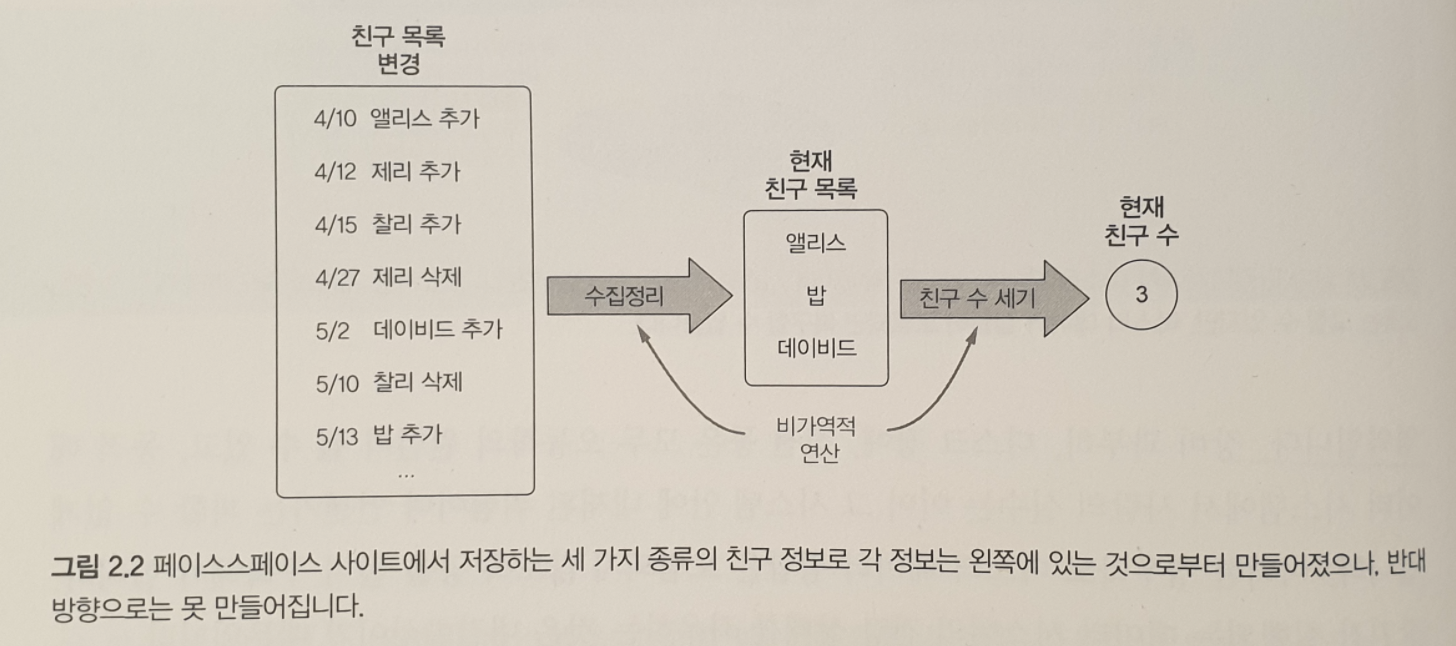
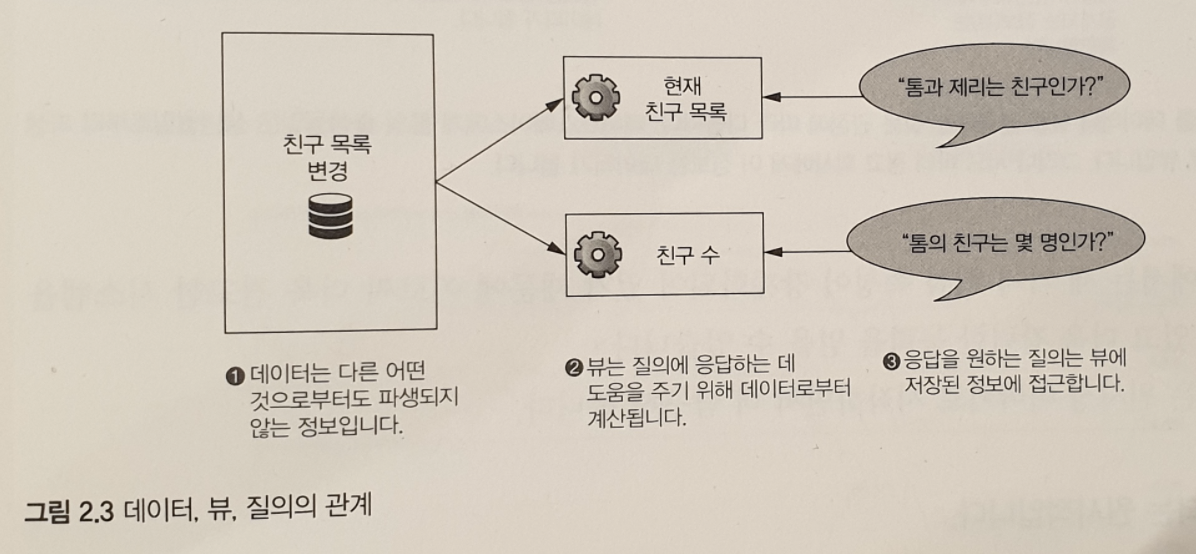
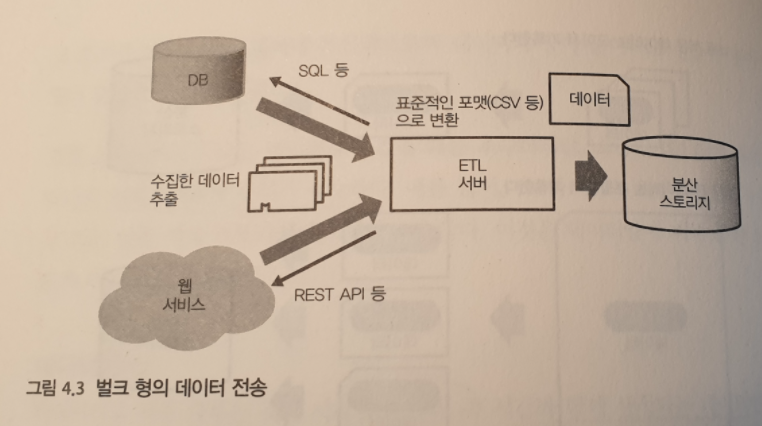
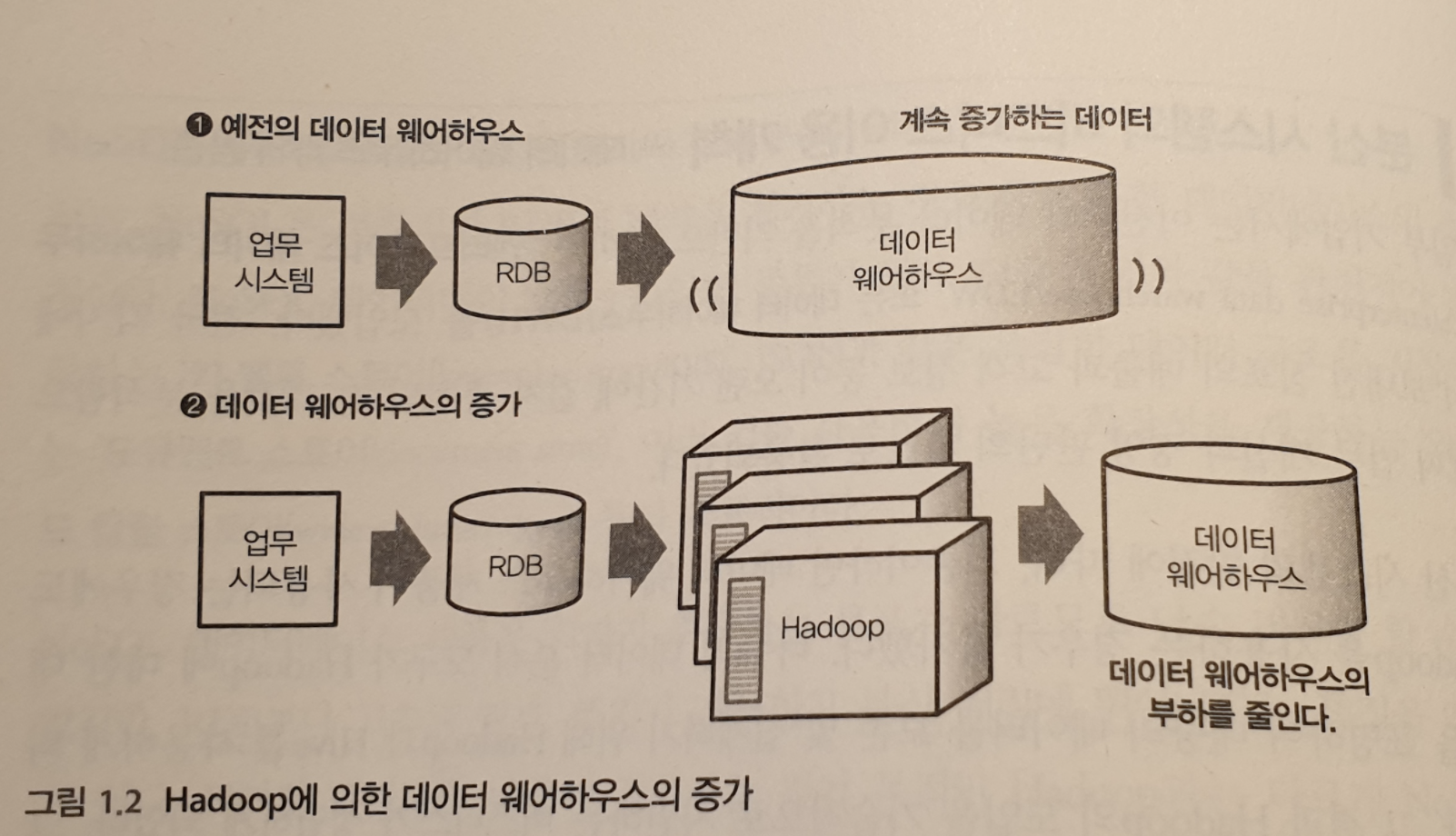
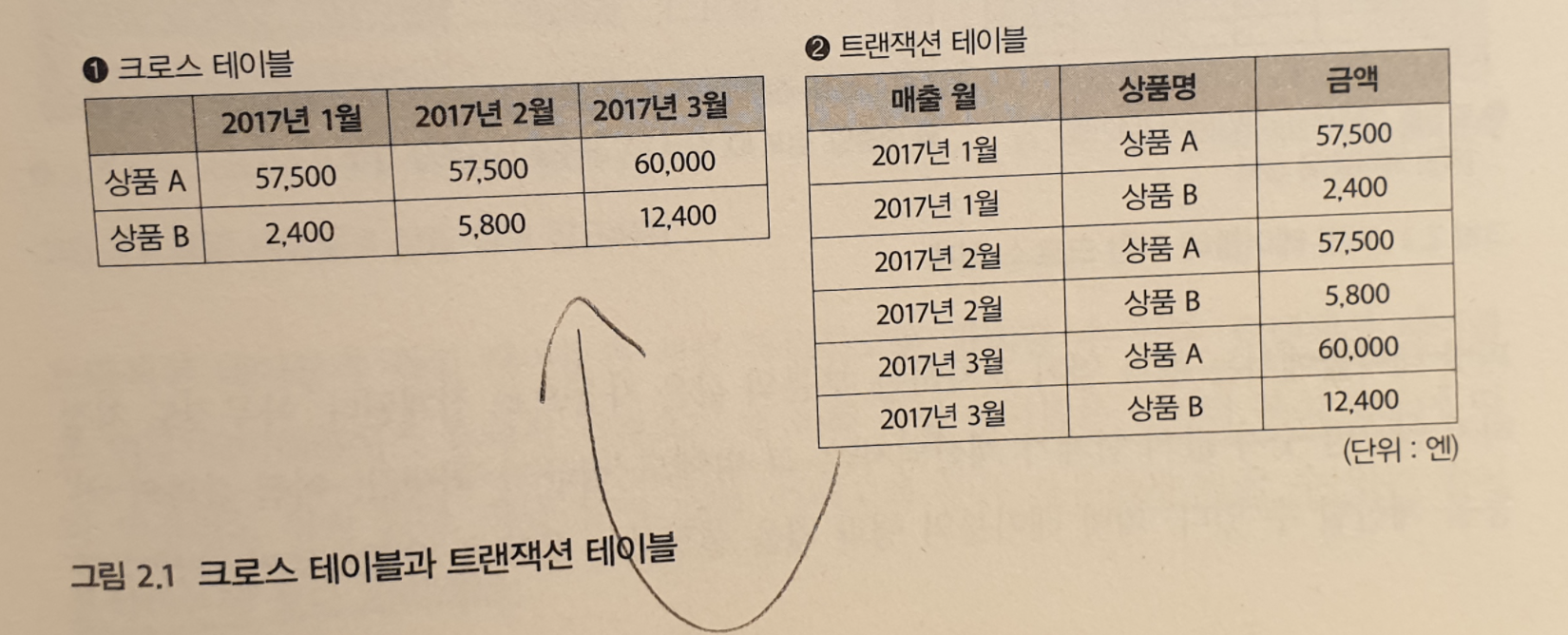
1.1 이 책의 구성
이론을 다루는 장과 사례를 다루는 장으로 나뉜다. 이론을 다루는 장은 빅데이터 시스템을 구축하는 방법을 다루고, 사례를 다루는 장에서는 이론을 구체적인 도구에 연관시킨다.
1.2 전통적인 데이터베이스를 사용해 확장하기
간단한 웹 분석 어플리케이션을 개발한다고 하자. 고객의 웹 페이지는 페이지뷰가 발생할 때마다 애플리케이션의 웹서버에 URL 정보를 보내야한다. 웹 서버는 데이터베이스에 페이지뷰에 해당하는 row 의 값을 증가시킨다. 이제 애플리케이션에 개선되며 어떤 문제가 생기는지 살펴본다.
1.2.1 큐를 사용해 확장하기
백엔드의 데이터베이스가 부하를 견디지 못해 페이지 뷰를 증가시키는 쓰기 요청을 신속히 처리하지 못해 타임 아웃이 나고 있다고 하자.
웹 서버가 데이터베이스에 직접 접근하도록 하는 대신, 웹 서버와 데이터베이스 사이에 큐를 넣는다. 그래서, 페이지뷰 이벤트를 받을 때마다 이벤트는 큐에 추가된다. 그리고, 큐에서 한 번에 100개씩 이벤트를 꺼내 하나의 데이터베이스 갱신 요청으로 일괄 처리하는 작업자 프로세스를 추가한다.
1.2.2 데이터베이스를 샤딩하여 확장하기
이 웹 분석 애플리케이션이 계속 인기가 높아져, 데이터베이스에 과부하가 다시 걸렸다고 하자. 기존의 작업자 프로세스로는 쓰기 요청을 감당할 수 없어 갱신을 병렬 처리 하기 위해 작업자 프로세스의 수를 늘렸보았지만 도움이 되지 않았다.
그래서, 데이터베이스 서버를 여러 대 사용하고 테이블을 여러 서버에 분산시키는 수평 분할, 또는 샤딩이라고 불리는 방법을 사용한다. 즉, 각 서버는 전체 테이블의 일부를 가지는 것이다. 쓰기 부하를 여러 서버, 즉 샤드로 분산 시키게 되는 것이다.
이 애플리케이션의 인기가 높어져, 데이터베이스를 더 많은 샤드로 나누었다고 하자. 샤드 개수가 변경되어서 기존의 애플리케이션 코드에도 반영을 해야하고 이것을 깜빡하면 의도하지 않은 샤드에 기록된다.
1.2.3 내결함성 문제 발생 시작
어쨌든 샤드를 늘렸는데, 이제 데이터베이스 장비에서 디스크 장애가 발생하는 상황이 왔다. 디스크 장애가 발생한 장비가 다운된 동안엔 그 디스크에 저장된 데이터를 사용할 수 없다. 해결책으로는,