[빅데이터를 지탱하는 기술] 3장_빅데이터 분산처리
1. 대규모 분산 처리의 프레임워크
비구조화 데이터를 읽어 들여 열 지향 스토리지로 변환하는 과정에서, 데이터의 가공 및 압축을 위해 많은 컴퓨터 리소스가 소비된다.
그래서 사용하는 것이 Hadoop, Spark 같은 분산 처리 프레임워크다.
구조화 데이터, 비구조화 데이터, 스키마리스 데이터
구조화 데이터
스키마가 명확하게 정의된 데이터.
기존의 데이터 웨어하우스에서는 항상 구조화 데이터로 축적하는 것이 일반적이었다.비구조화 데이터
스키마가 없는 데이터.
이 상태로는 SQL 로 제대로 집계할 수 없다.스키마리스 데이터
CSV, JSON, XML 등의 데이터는 서식은 정해져 있지만, 칼럼 수나 데이터 형은 명확하지 않다.
데이터 구조화의 파이프라인
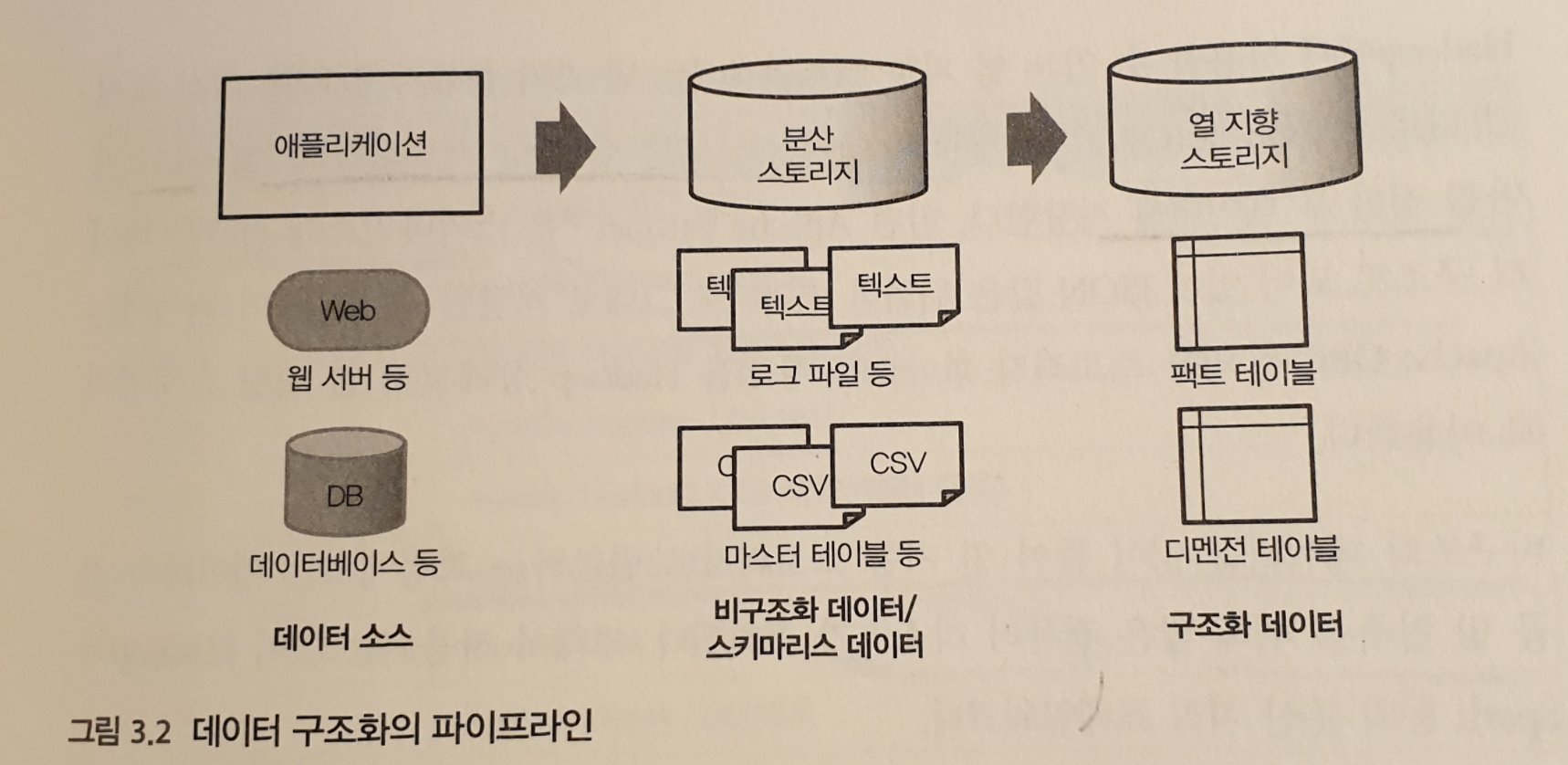
분산 스토리지에 수집된 데이터는 명확한 스키마를 갖지 않아 그대로는 SQL 로 집계할 수 없다.
그래서, 먼저 스키마를 명확하게 한 테이블 형식으로 변환해야한다.
구조화된 데이터는 데이터 압축률을 높이기 위해 열 지향 스토리지에 저장한다.
열 지향 스토리지의 작성
Hadoop 의 열 지향 스토리지는,
Apache ORC
처음에 스키마를 정한 후 데이터를 저장Apache Parquet
스키마리스에 가까운 데이터 구조로 되어 있어서 JSON 같은 데이터도 그대로 저장