Atomicity 트랜잭션 내에서 실행한 작업들은 하나의 작업 처럼, 모두 성공하거나 모두 실패해야한다.
Consistency 트랜잭션은 일관성 있는 데이터베이스 상태를 유지해야한다. 예를 들면, 데이터베이스의 무결성 제약 조건을 항상 만족해야한다.
Isolation 동시에 실행되는 트랜잭션은 서로 영향을 미치지 않아야한다.
Durability 트랜잭션을 성공적으로 끝내면, 그 결과가 데이터베이스에 항상 기록되어야한다.
문제는 격리성이다. 트랜잭션간에 완벽하게 격리성을 보장하기 위해서는 어떻게 해야할까 ? 트랜잭션을 차례대로 실행해야한다. 그러면, 동시성이 처리 기능이 떨어진다. 그래서 트랜잭션 격리 수준이 등장한다.
Isolation Level
격리 수준이 낮을 수록 더 많은 문제가 발생한다. READ UNCOMMITTED, READ COMMITTED , REPEATABLE READ, SERIALIZABLE 으로 격리 수준이 높아진다. 애플리케이션은 대부분 동시성 처리가 중요하기 때문에, 데이터베이스들은 보통 READ COMMITTED 격리 수준이 기본이다.
@Controller classHelloController{ @Autowired HelloService helloService; publicvoidhello(){ //반환된 member 엔티티는 준영속 상태 Member member = helloService.logic(); } }
@Service classHelloService{ // 엔티티 메니저 주입 @PersistenceContext EntityManager em; @Autowired Repository1 repository1; @Autowired Repository2 repository2; //트랜잭션 시작 @Transactional publicvoidlogic(){ repository1.hello(); //Member 는 영속상태 Member member = repository2.findMember(); return member; } //트렌젝션 종료 }
@Repository classRepository2{ @PersistenceContext EntityManager em; public Member findMember(){ return em.find(Member.class, "id1"); //영속성 컨텍스트 접근 } }
준영속 상태와 지연 로딩
조회한 엔티티가 서비스와 리포지토리 계층에서는 영속성 컨텍스트에 관리되면서 영속 상태를 유지하지만, 컨트롤러나 뷰 같은 프리젠테이션 계층에서는 준영속 상태가 된다. 따라서, 변경감지와 지연로딩이 동작하지 않는다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
@Entity publicclassOrder{ @Id@GeneratedValue private Long id; @ManyToOne(fetch = FetchType.LAZY)// 지연로딩 private Member member; // 주문 회원 }
classOrderController{ public String view(Long orderId){ Order order = orderService.findOne(orderId); Member member = order.getMember(); member.getName(); // 지연로딩 시 예외 발생 } }
변경감지 기능이 프리젠테이션 계층에서 동작하지 않는 것은 문제가 되지 않는다. 변경 감지 기능이 프리젠테이션 계층에서도 동작하면 애플리케이션 계층이 가지는 책임이 모호해지고, 데이터를 어디서 어떻게 변경했는지 프리젠테이션 계층까지 다 찾아야 하므로 유지보수하기 어렵다. 비즈니스 로직은 서비스 계층에서 끝내야한다.
publicclassMemberRepository{ @PersistenceContext EntityManager em; publicvoidsave(Member member){...} public Member findOne(Long id){...} public List<Member> findAll(){...} public Member findByUsername(String username){...} }
publicclassItemRepository{ @PersistenceContext EntityManager em; publicvoidsave(Item item){...} public Member findOne(Long id){...} public List<Member> findAll(){...} }
위 코드를 보면, 회원 리포지토리와 상품 리포지토리가 하는 일이 비슷하다. 이 문제를 해결하려면 제네릭과 상속을 적절히 사용해서 공통 부분을 처리하는 부모 클래스를 만들면 된다. 이것을 보통 GenericDAO 라고 한다. 하지만 이것은, 공통 기능을 구현하는 부모 클래스에 종속되고 구현 클래스 상속이 가지는 단점이 있다.
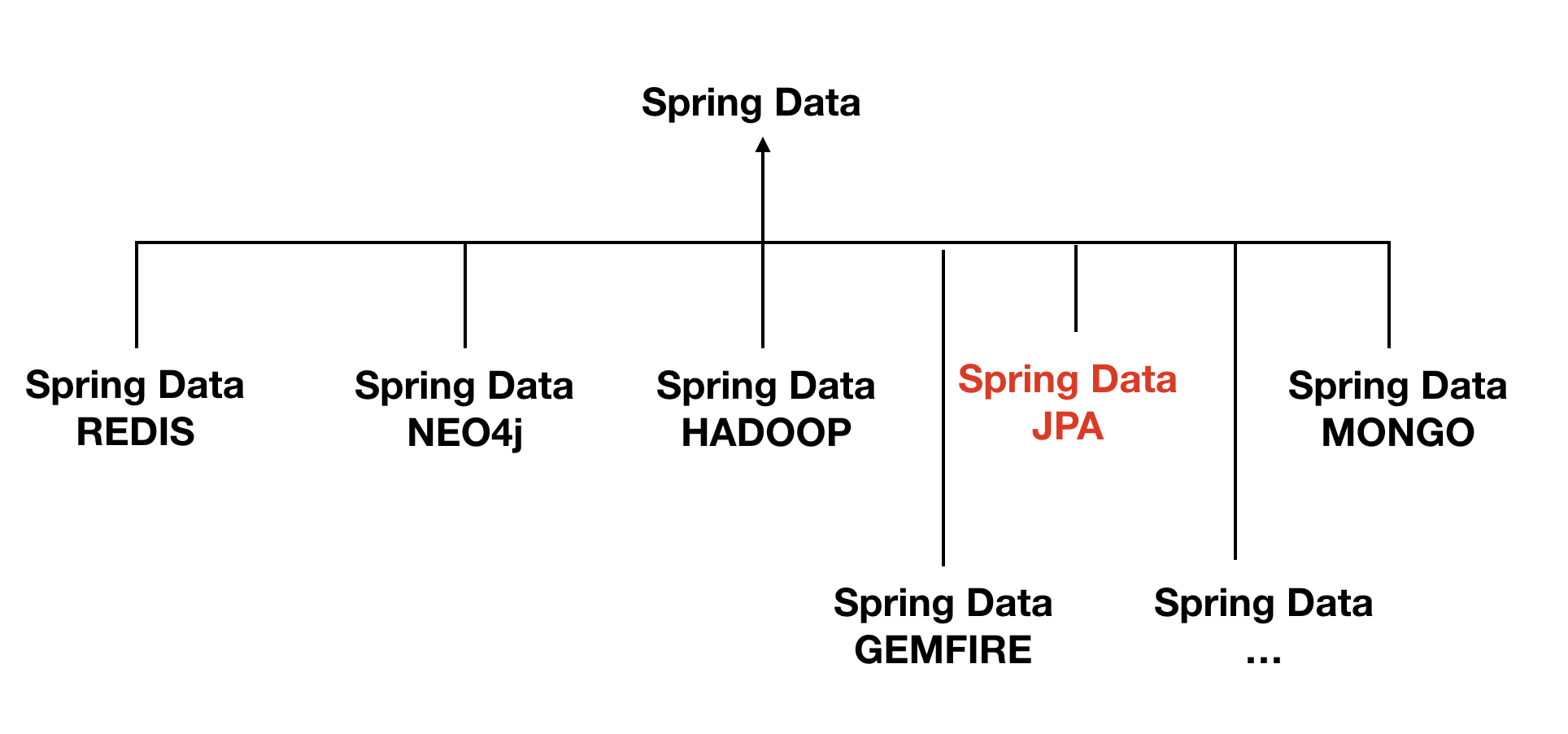
스프링 데이터 JPA
스프링 데이터 JPA 는 스프링 프레임워크에서 JPA 를 편리하게 사용할수 있도록 지원하는 프로젝트이다. 이 프로젝트는 데이터 접근 계층을 개발할 때 지루하게 반복되는 CRUD 문제를 세련된 방법으로 해결한다. 데이터 접근 계층을 개발할 때 구현 클래스 없이 인터페이스만 작성해도 개발을 완료할 수 있다.
1 2 3 4 5 6
publicinterfaceMemberRepositoryextendsJpaRepository<Member, Long> { Member findByUsername(String username); }
회원과 상품 리포지토리 구현체는 애플리케이션 실행 시점에 스프링 데이터 JPA 가 생성해서 주입해준다. 즉, 개발자가 직접 구현체를 개발하지 않아도 된다. 일반적인 CRUD 메소드는 JpaRepository 인터페이스가 공통으로 제공하지만, MemberRepository.findByUsername(…) 처럼 직접 작성한 공통으로 처리할 수 없는 메소드는 스프링 데이터 JPA 가 메소드 이름을 분석해서 JPQL 을 실행한다.
JPA 를 사용해서 테이블을 매핑할 클래스는 @Entity 를 필수로 붙여야한다. 그리고, @Entity 적용시 기본 생성자는 필수이다.
@Table
엔티티와 매핑할 테이블을 지정한다.
데이터베이스 스키마 자동 생성
JPA 는 클래스의 매핑 정보와 Database Dialect 을 사용해서 데이터베이스 스키마를 생성한다. create / create-drop / update / validate / none 옵션이 있다. 다음과 같이 설정하면 기존 테이블은 삭제하고 새로 생성한다. ( DROP + CREATE )