Consumer 를 추가하자. “jko-topic” 을 listen 하는 consumer 이다. CountDownLatch 는 테스트 할 때, producer 가 send 한 record 를 consumer thread 가 consume 을 완료할 때 까지 대기하기 위해 사용된다.
테스트를 작성할 때의 핵심은, 외부 카프카 서버에 의존하지 않고 테스트하는 것이다. 이를 위해, spring-kafka-test 에서 지원하는 @EmbeddedKafka 를 사용한다. @EmbeddedKafka 는, Spring for Apache Kafka 기반 테스트를 실행하는 테스트 클래스에 지정할 수 있는 어노테이션이다. 테스트를 실행할 때, in-memory kafka instance 를 사용하게 된다.
프로듀서란, 메세지를 생산해서 카프카의 토픽으로 보내는 역할을 하는 애플리케이션 or 서버이다. 주요 기능은, 각각의 메세지를 토픽 파티션에 매핑하고 파티션의 리더에 요청을 보내는 것이다. 프로듀서 옵션 중에 acks 옵션 설정에 따라 카프카로 메세지를 전송할 때, 메세지 손실 여부와 메세지 전송 속도 및 처리량이 달라진다.
메세지 보내고 확인하지 않기 메세지 손실 가능성이 있다.
동기 전송 카프카의 응답을 기다린다.
비동기 전송 응답을 기다리지 않기 때문에 빠른 전송이 가능하다.
메세지 손실 가능성 높음 && 빠른 전송 속도
acks = 0 카프카 서버의 응답을 기다리지 않고 메세지 보낼 준비가 되면 즉시 다음 요청을 보낸다.
메세지 손실 가능성 낮음 && 적당한 전송 속도
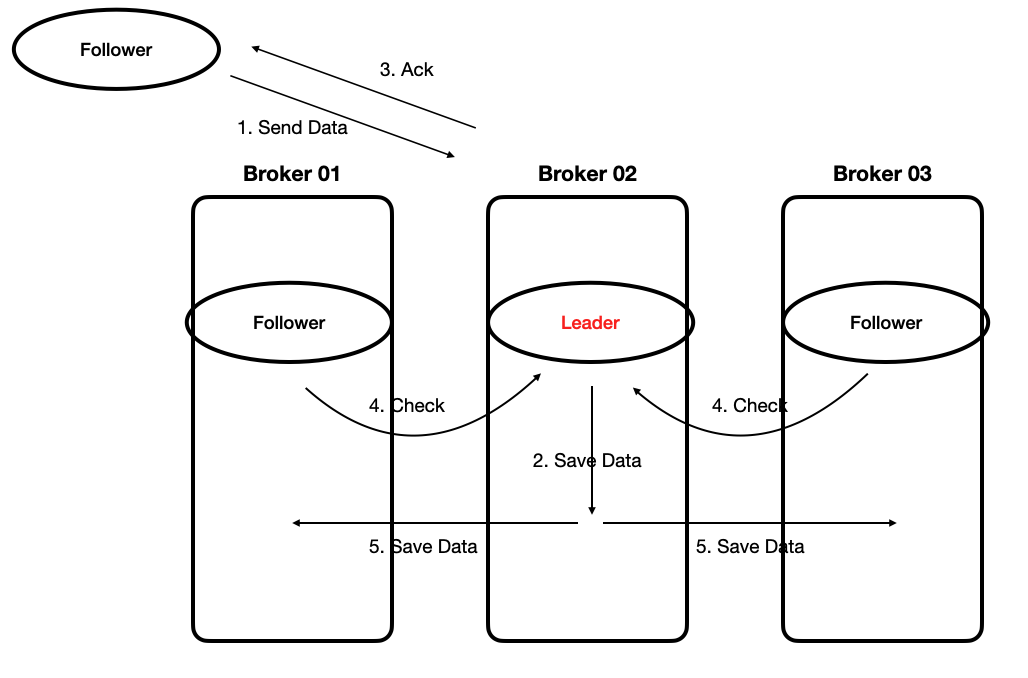
asks = 1 프로듀서는 메세지를 보내고 Leader 는 잘 받았으면, 바로 ack 를 한다. 팔로워들은 주기적으로 리더를 확인하고 새로운 메세지가 확인되면 팔로워들에도 저장한다. 메세지 손실이 발생하는 경우는 리더에 장애가 발생하는 경우이다. 즉, 프로듀서가 리더에게 메세지를 보내고 리더는 메시지를 저장한 후에 바로 장애가 발생하는 경우이다.
메세지 손실 없음 && 느린 전송 속도
acks = all 메세지를 보내고 잘 받았는지 확인하고 추가적으로 팔로워들까지 메세지를 잘 받았는지 확인한다. 이 때, 프로듀서 설정 뿐만 아니라 브로커 설정도 같이 해줘야한다.